17 Arbeiten mit Zeitreihen
17.1 Zeitreihen
Begriff der Zeitreihe
Eine “Zeitreihe” ist eine zeitlich geordnete Folge von Beobachtungen, bei der sich die Anordnung der Merkmalsausprägungen zwingend aus dem Zeitablauf ergibt (etwa Aktienkurse, Bevölkerungsentwicklung, Wetterdaten).
Die einzelnen Zeitpunkte werden zu einer Menge von Beobachtungszeitpunkten \(T\) zusammengefasst, bei der für jeden Zeitpunkt \(t \in T\) genau eine Beobachtung vorliegt. Zeitreihen treten in fast allen Bereichen der Wissenschaft auf.
Zeitreihen in R
Das R-Paket tsibble stellt eine Datenstruktur (das tsibble - wie tibble aus dem tidyverse wobei ts für Time Series steht) sowie verschiedene Funktionen bereit, die das Arbeiten mit Zeitreihen vereinfachen.
Datenstruktur tsibble
- Gehört zu den Paketen aus dem
tidyverts - Variable mit Zeit wird als Index bezeichnet
- Link zur Einführung
- Normalen Dataframe mit
as_tsibbleintsibblekonvertieren- Zeitpunkte dürfen nicht doppelt vorkommen
- Angeben, welche Variable Index sein soll
17.2 Winddaten vom Deutschen Wetterdienst
Übersicht Stationen
data("metaIndex")
d_stationen <- metaIndex |>
filter(var == "wind", res == "10_minutes") |>
mutate(Dauer = round(as.numeric(bis_datum - von_datum) / 365.25)) |>
arrange(desc(Dauer)) |>
select(von_datum, bis_datum, Dauer, Stationsname, Bundesland) |>
as_tibble()
d_stationenDaten herunterladen und Zwischenspeichern
if (!file.exists("daten/d_wind_raw.RData")) {
d_wind_raw <- selectDWD(name = "Helgoland", res = "10_minutes", var = "wind", per = "historical", current = TRUE) |>
dataDWD() |>
bind_rows()
save(d_wind_raw, file = "daten/d_wind_raw.RData")
} else {
load(file = "daten/d_wind_raw.RData")
}Rohdaten anschauen
d_wind_raw |>
group_by(MESS_DATUM) |>
mutate(n = n()) |>
filter(n > 1) |>
arrange(MESS_DATUM) |>
select(MESS_DATUM, FF_10, n) |> ungroup()Es gibt einige Zeitpunkte doppelt
Winddaten aufbereiten und in tsibble konvertieren
d_wind_raw_ts <- d_wind_raw |>
select(Station = STATIONS_ID, Datum = MESS_DATUM, Geschwindigkeit = FF_10) |>
distinct(Datum, .keep_all = TRUE) |>
as_tsibble(key = Station, index = Datum)# A tsibble: 1,454,109 x 3 [10m] <GMT>
# Key: Station [1]
Station Datum Geschwindigkeit
<int> <dttm> <dbl>
1 2115 1996-12-19 10:40:00 15.8
2 2115 1996-12-19 10:50:00 16.2
3 2115 1996-12-19 11:00:00 16.6
4 2115 1996-12-19 11:10:00 16
5 2115 1996-12-19 11:20:00 16.3
6 2115 1996-12-19 11:30:00 16.3
7 2115 1996-12-19 11:50:00 16.8
8 2115 1996-12-19 12:00:00 9.4
9 2115 1996-12-19 12:10:00 15.2
10 2115 1996-12-19 12:20:00 16.2
# ℹ 1,454,099 more rows- Mehrfachbeobachtungen mit
distinct()entfernen - In tsibble: Zusatzinformation zu Index und Schlüssel
Plot der Rohdaten
ggplot(data = d_wind_raw_ts) +
geom_line(mapping = aes(x = Datum, y = Geschwindigkeit))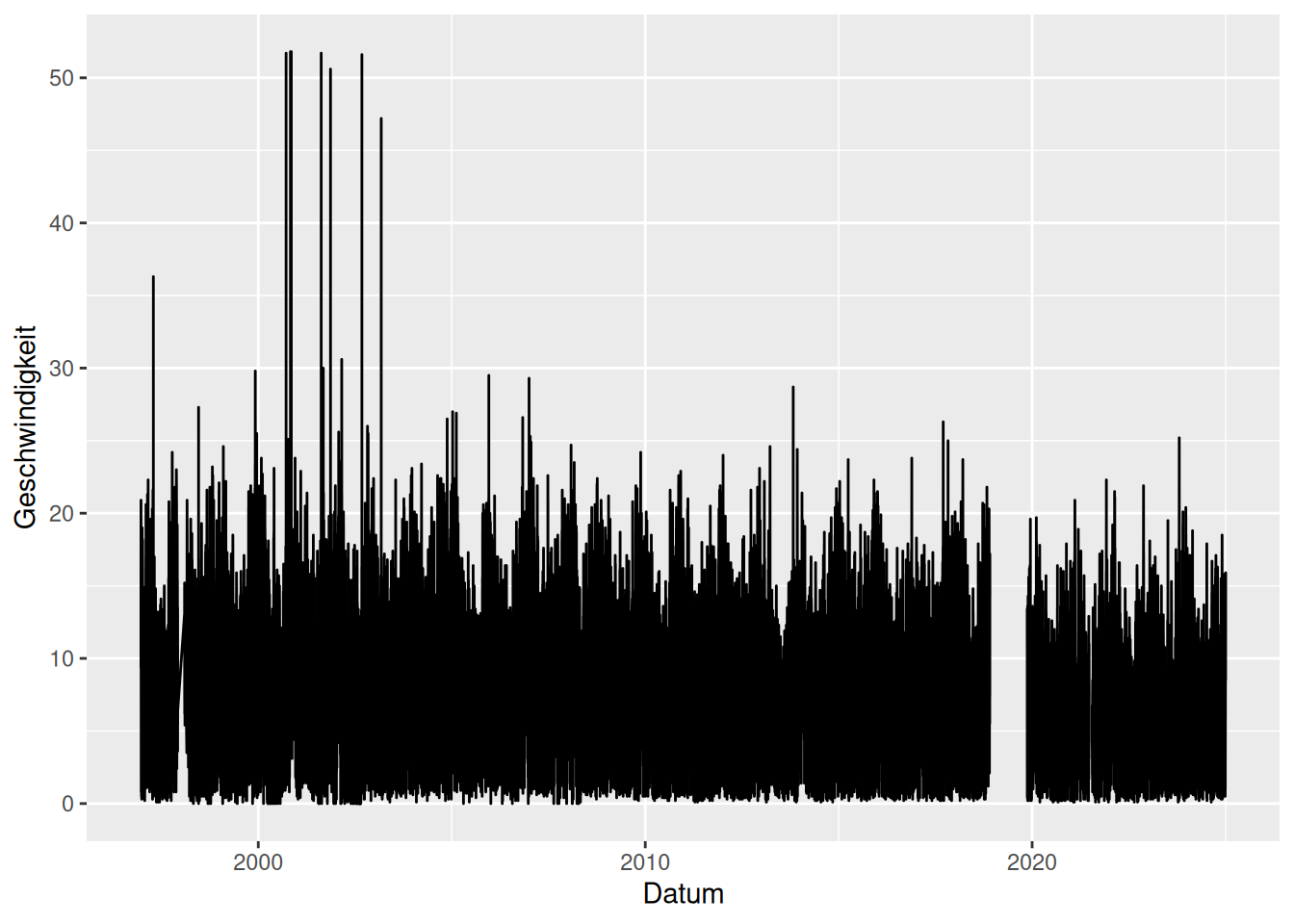
Lücken im Datensatz, erste Lücke mit Linie verbunden!
Lücken listen mit count_gaps
d_wind_raw_ts |> count_gaps()Lücken listen mit count_gaps
d_wind_raw_ts |> count_gaps() |> filter(.n >= 10)Lücken auffüllen mit fill_gaps
d_wind <- d_wind_raw_ts |> fill_gaps()nrow(d_wind_raw_ts)[1] 1454109nrow(d_wind)[1] 1474496
Fehlende Beobachtungen mit NA aufgefüllt.
Plot
ggplot(d_wind) +
geom_line(mapping = aes(x = Datum, y = Geschwindigkeit))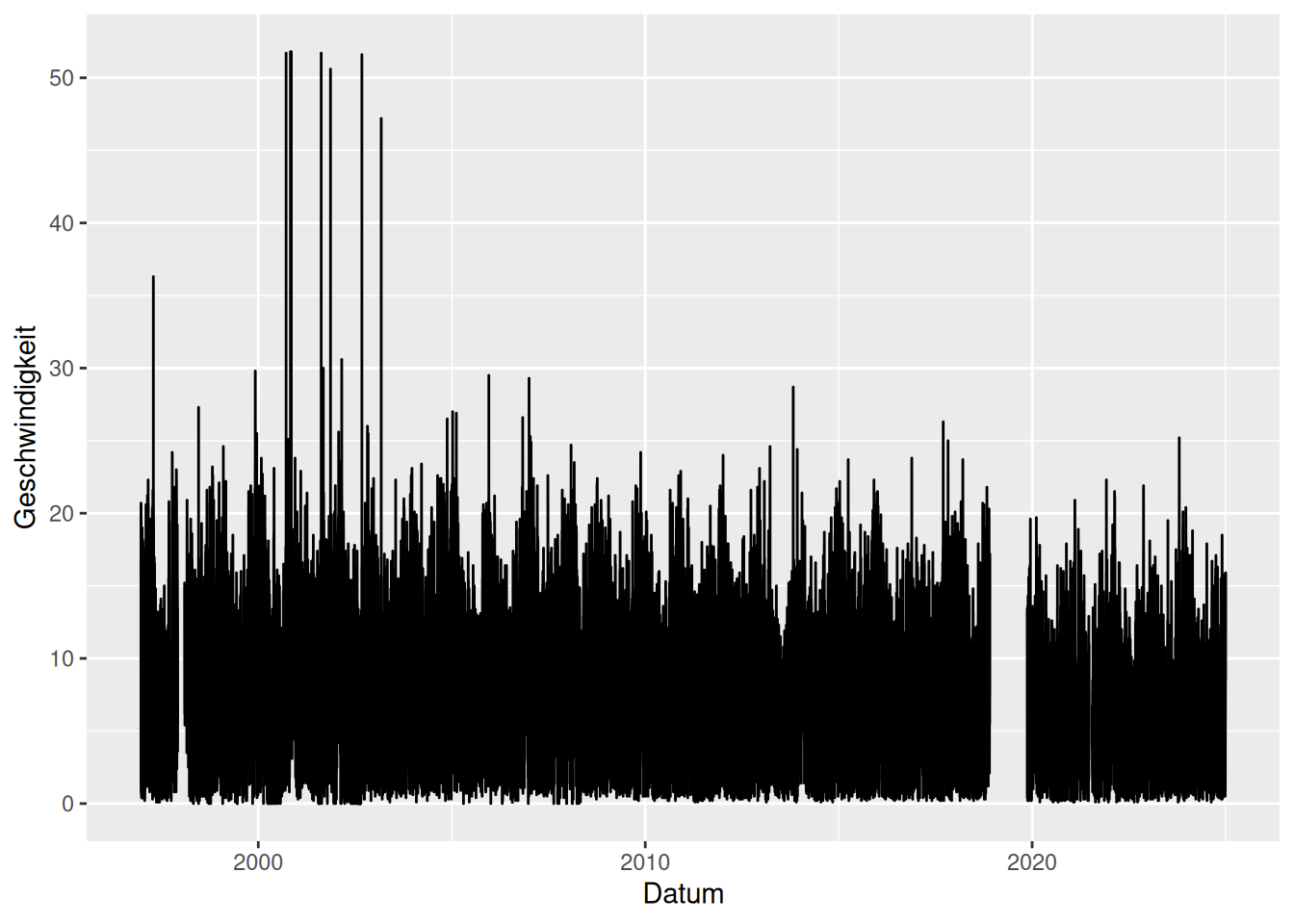
\(\rightarrow\) Lücken werden als Lücken dargestellt
Starkwindereignisse
Ereignis: Windgeschwindigkeit innerhalb von 2 Stunden nicht unter 10 m/s und mindestens einmal über 20 m/s (Beispiel, kein Kriterium des DWD)
d_wind_stark <- d_wind |>
mutate(
v_min_120 = roll_minr(Geschwindigkeit, n = 12, na.rm = TRUE),
v_max_120 = roll_maxr(Geschwindigkeit, n = 12, na.rm = TRUE)
) |>
filter(v_min_120 >= 10, v_max_120 >= 20)Funktionen roll_minr und roll_maxr suchen aus n = 12 Werten (aktuell und 11 vorangegangene) kleinsten und größten Wert heraus. Analog für Summe, Mittelwert und so weiter.
Plot
ggplot(data = d_wind_stark) +
geom_line(mapping = aes(x = Datum, y = v_min_120))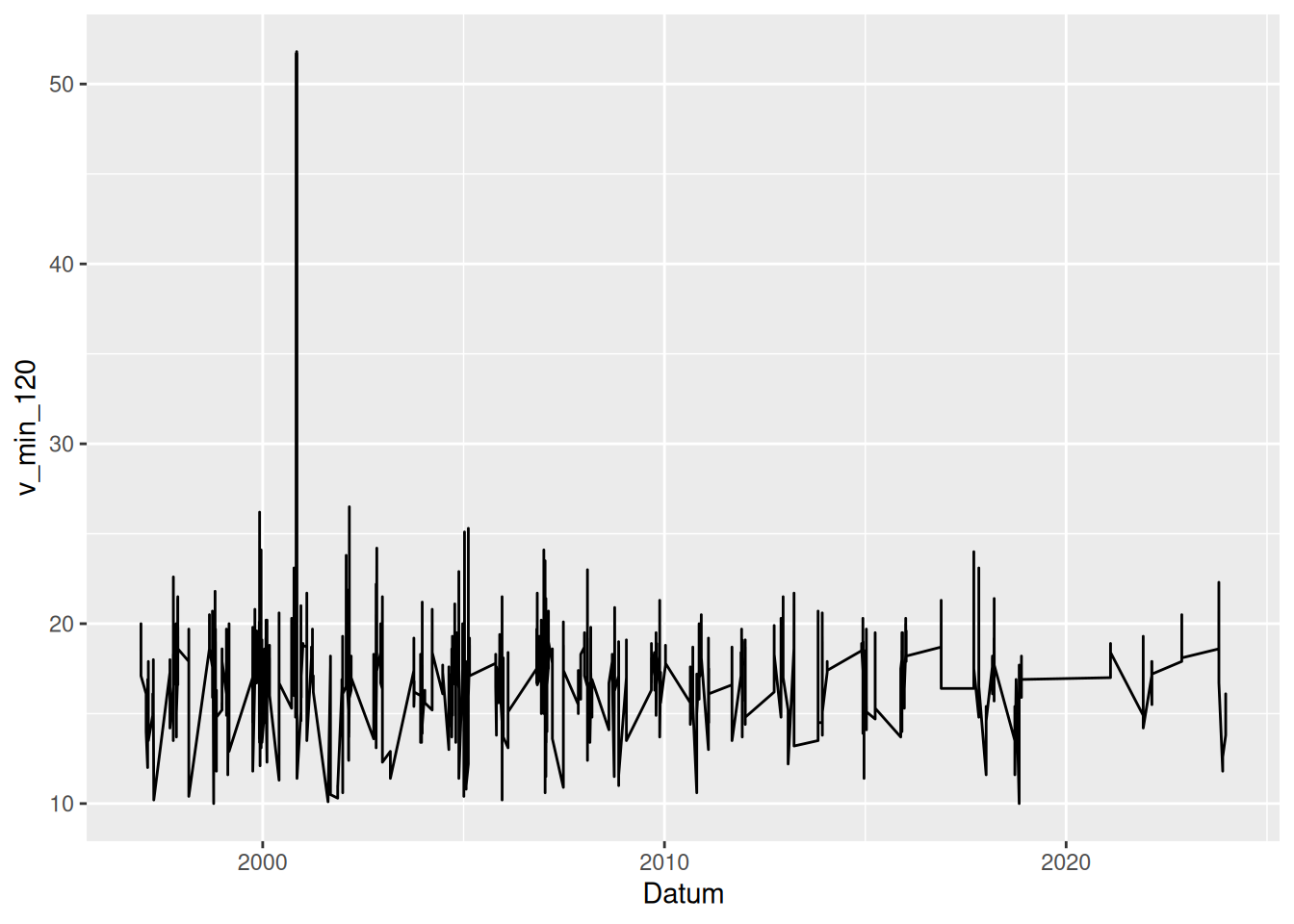
\(\rightarrow\) Einzelne Ereignisse sind nicht zu unterscheiden!
Ereignisse gruppieren
d_wind_stark_g <- d_wind_stark |>
mutate(
neue_gruppe = Datum - lag(Datum, default = dmy("01/01/1979")) > 10,
gruppe = cumsum(neue_gruppe)
)Neue Gruppe falls Abstand zwischen Beobachtungen größer 10 Minuten. In cumsum wird FALSE = 0 und TRUE = 1 verwendet.
Plotten mit Gruppe
ggplot(data = d_wind_stark_g) +
geom_line(mapping = aes(x = Datum, y = Geschwindigkeit, group = gruppe, color = factor(gruppe)), show.legend = FALSE)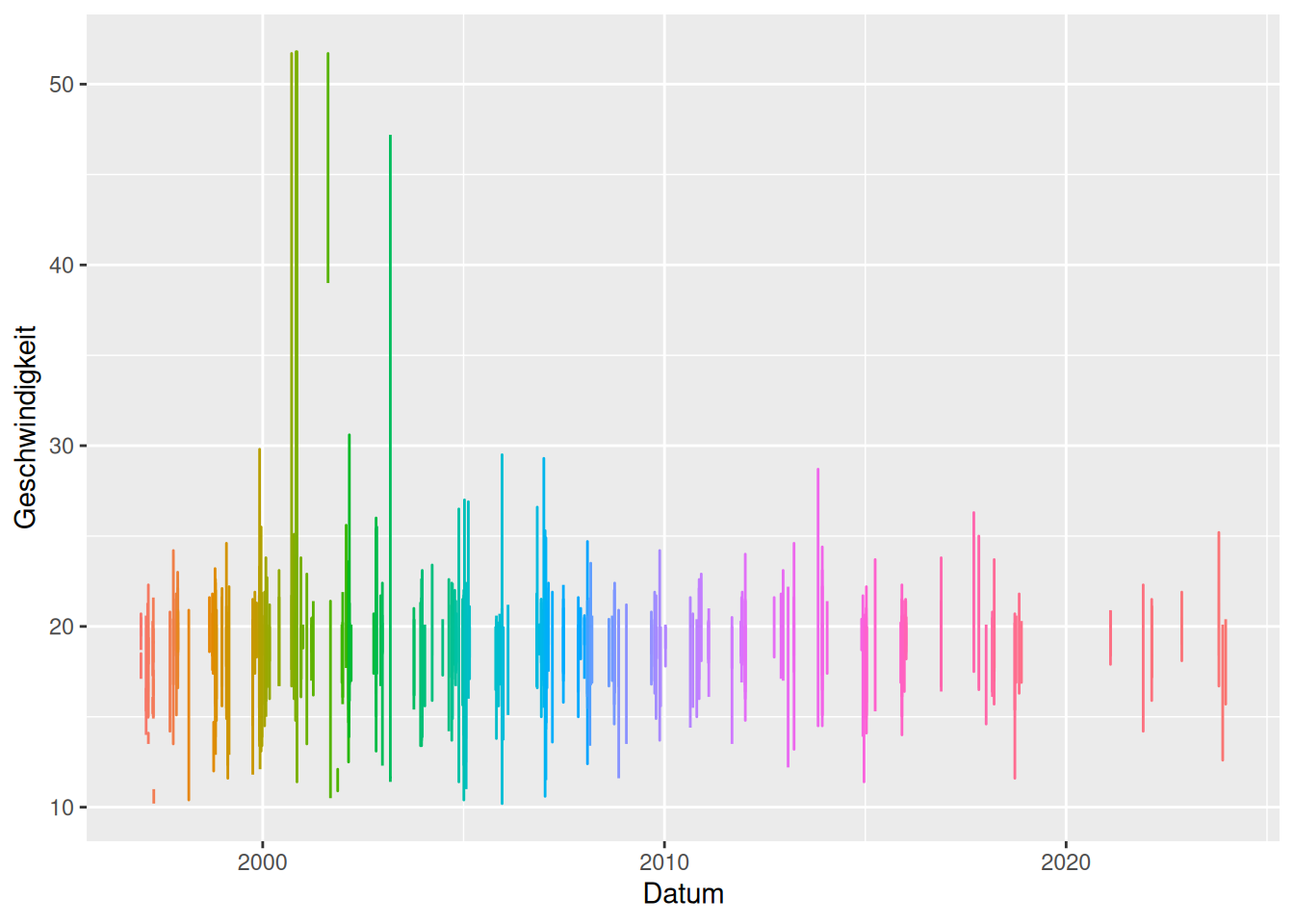
Ereignisse zusammenfassen
d_starkwindereignisse <- d_wind_stark_g |>
as_tibble() |>
group_by(gruppe) |>
summarise(start = min(Datum), dauer = max(Datum) - min(Datum), v_max = max(v_max_120))Mit as_tibble wieder in ‘normalen’ Dataframe umwandeln damit group_by funktioniert wie gewohnt
Gruppe 82
ggplot(data = d_wind_stark_g |> filter(gruppe == 82)) +
geom_line(mapping = aes(x = Datum, y = Geschwindigkeit))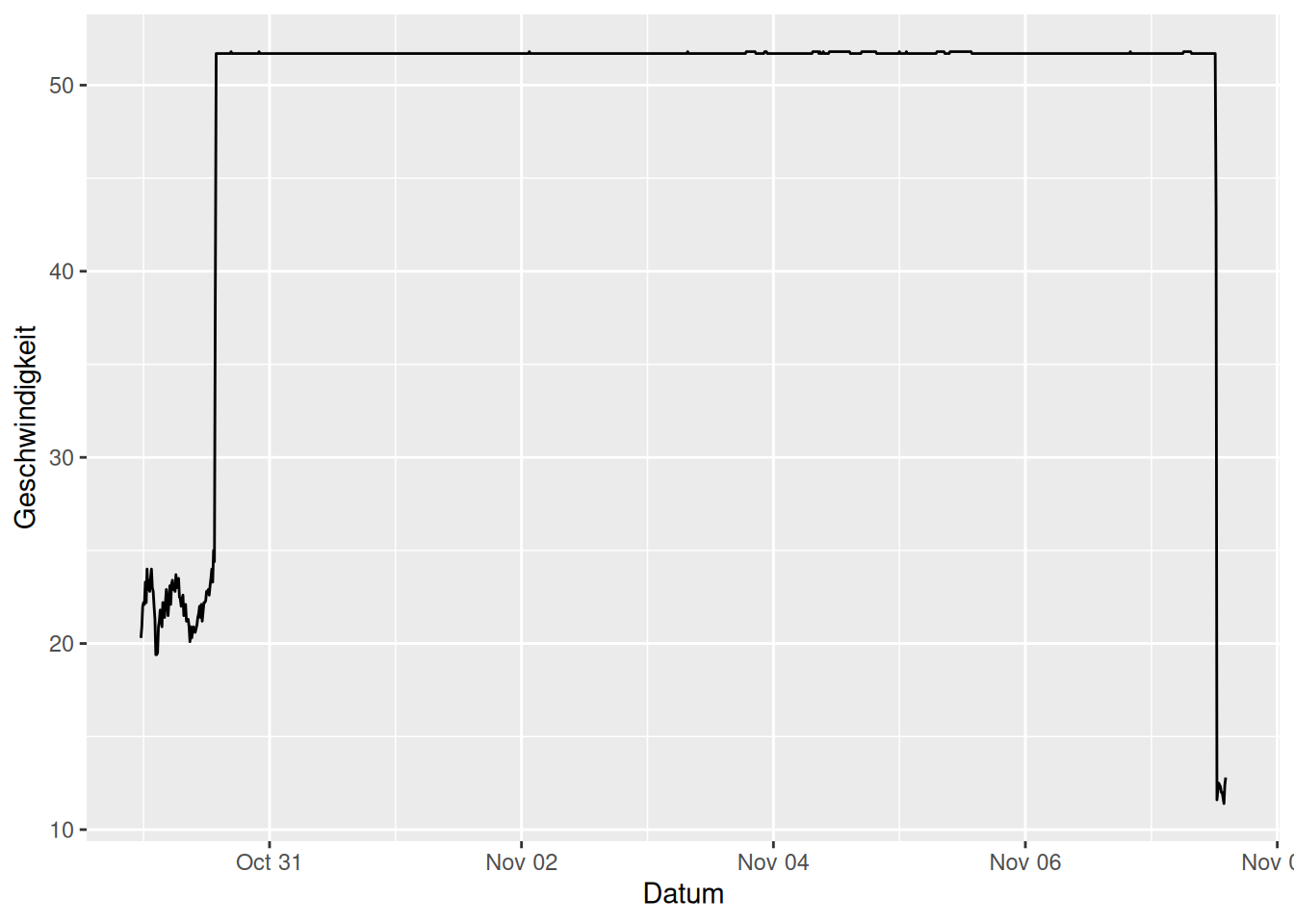
Sieht komisch aus, Rohdaten plotten
Wind im Oktober/November 2000
ggplot(mapping = aes(x = Datum, y = Geschwindigkeit)) +
geom_line(data = d_wind) +
geom_line(data = d_wind_stark_g |> filter(gruppe == 82), color = "hotpink") +
coord_cartesian(xlim = c(dmy_h("29/10/2000:12"), dmy_h("8/11/2000:0")))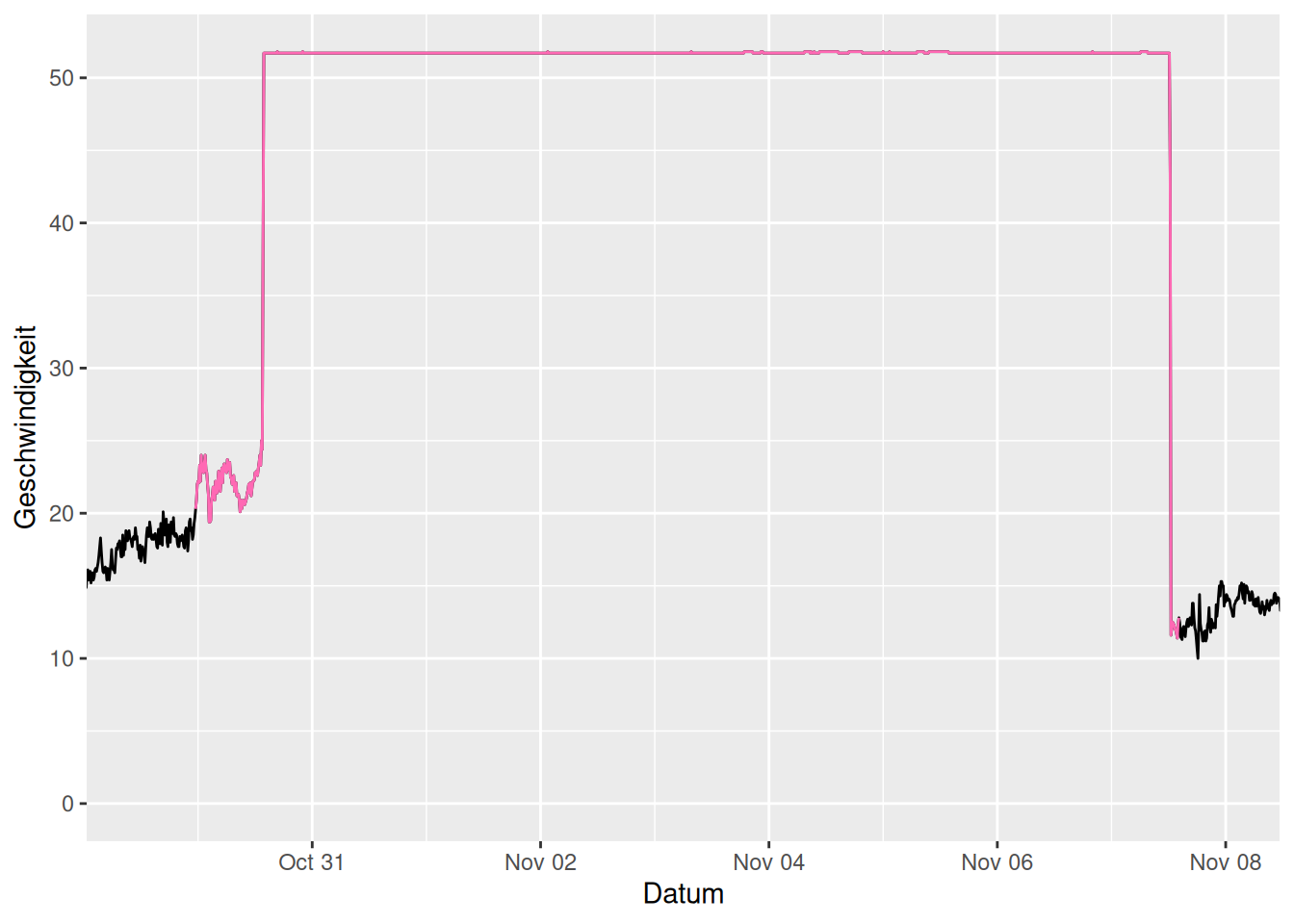
Plateau nicht realistisch, Vermutung: Messgerät im Orkan Oratia kaputt gegangen. Müsste man bei der Auswertung berücksichtigen.
Histogramm Windgeschwindigkeiten
ggplot(data = d_starkwindereignisse) +
geom_histogram(mapping = aes(x = v_max), binwidth = 0.5)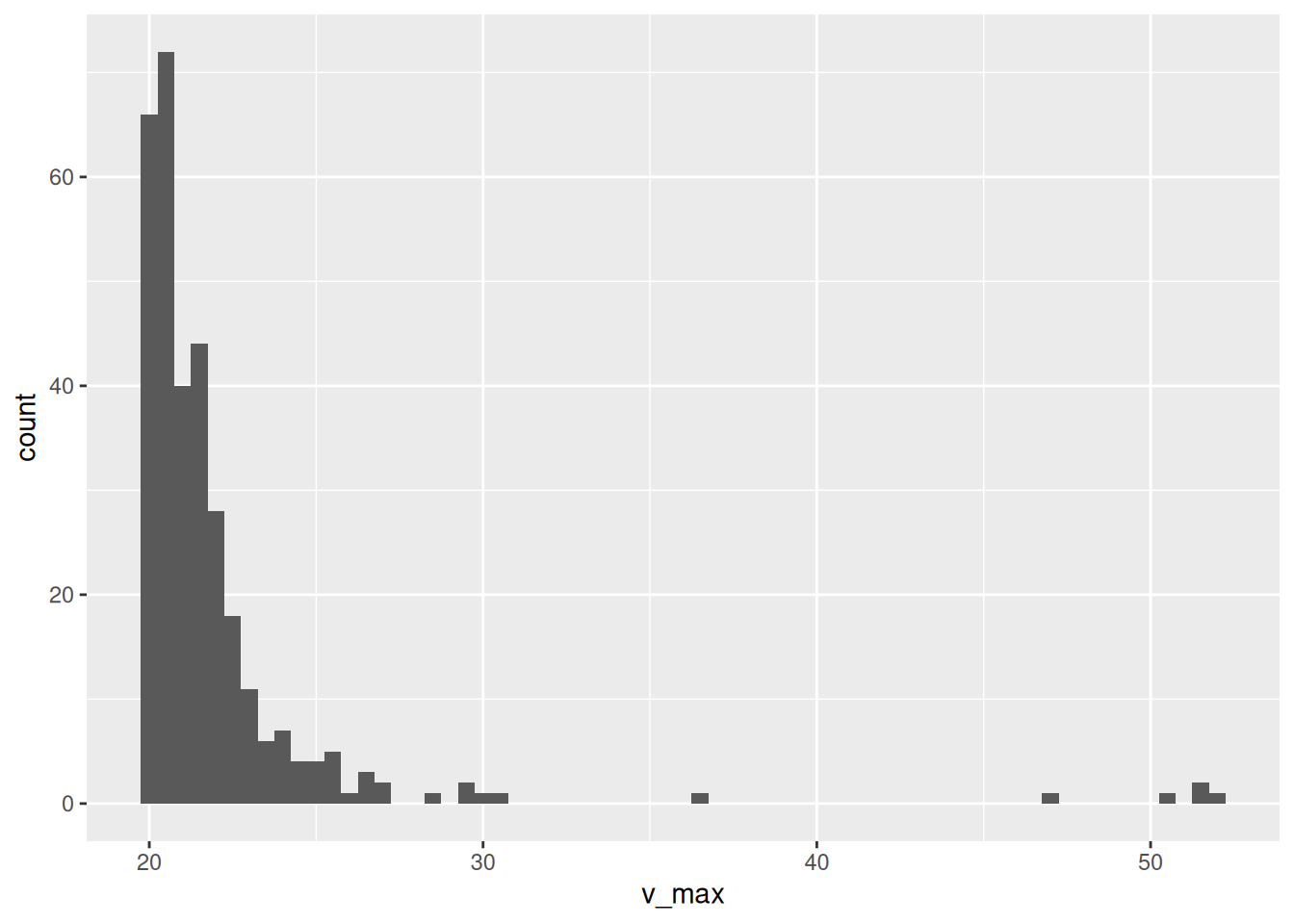
Histogramm Dauer
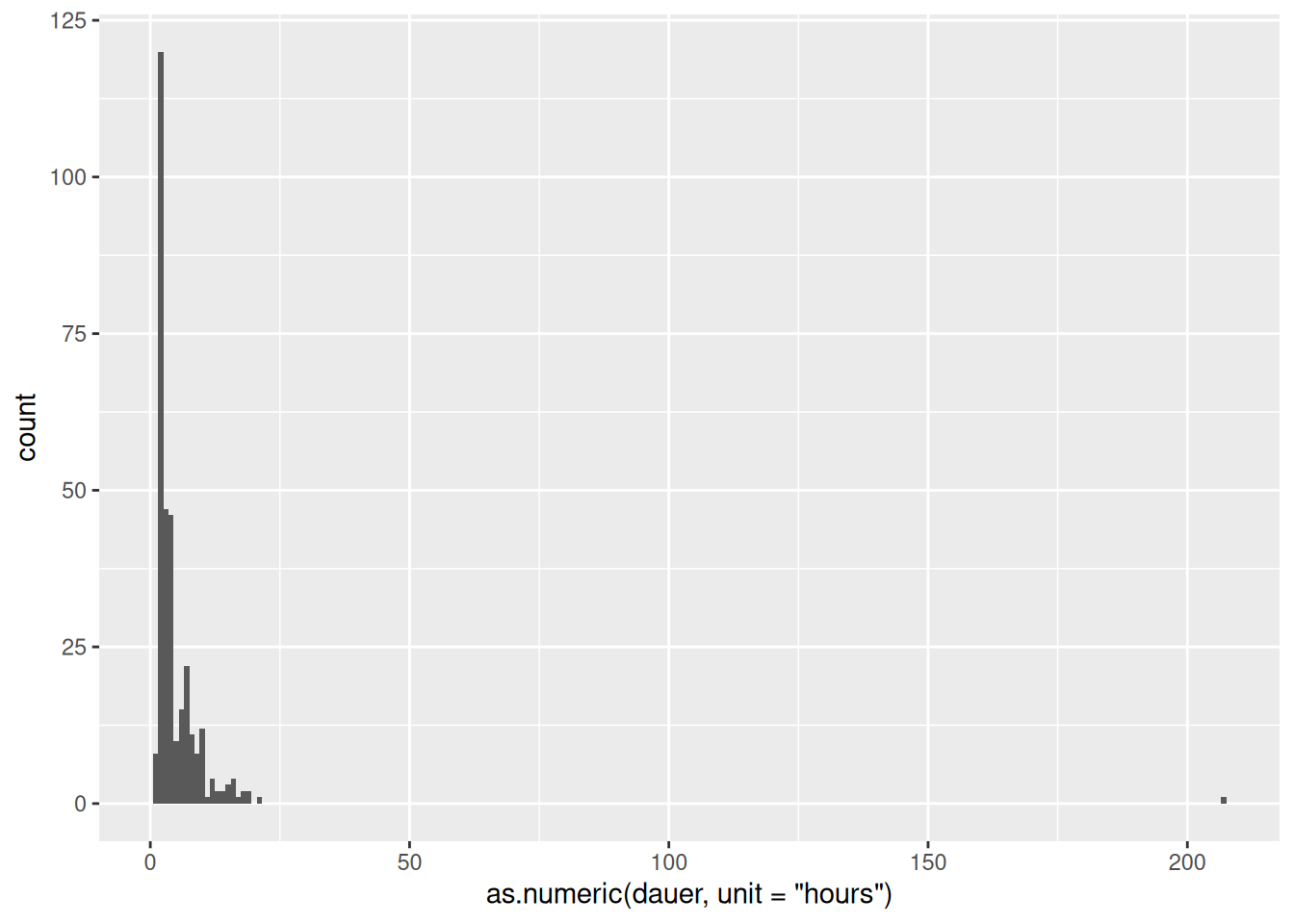
ggplot(data = d_starkwindereignisse) +
geom_histogram(mapping = aes(x = as.numeric(dauer, unit = "hours")), binwidth = 1)