library(readxl)10 Daten einlesen
10.1 Tidyverse
Tidyverse

- Sammlung von Bibliotheken für Data-Science in R
- Durchgängige Designphilosophie und Datenstrukturen
- Viele Dinge leichter und eleganter zu erledigen als in ‘reinem’ R
- Ursprünglich von Hadley Wickham, heute viele Entwickler
- Einführung vom Autor auf Youtube (englisch)
10.2 Excel-Dateien lesen
Funktion read_excel(...)
Paket laden
Tabelle einlesen
d <- read_excel(Dateiname, Argumente...)Die wichtigsten Argumente
| Argument | Bedeutung | Optional |
|---|---|---|
| skip = 5 | Anzahl zeilen, die überlesen werden sollten | Ja |
| range = “B2:G5” | Einzulesender Bereich (ersetzt skip) |
Ja |
| sheet = “Name” | Tabellenblatt, das gelesen werden soll | Ja |
Beispiel 1: Einfache Tabelle
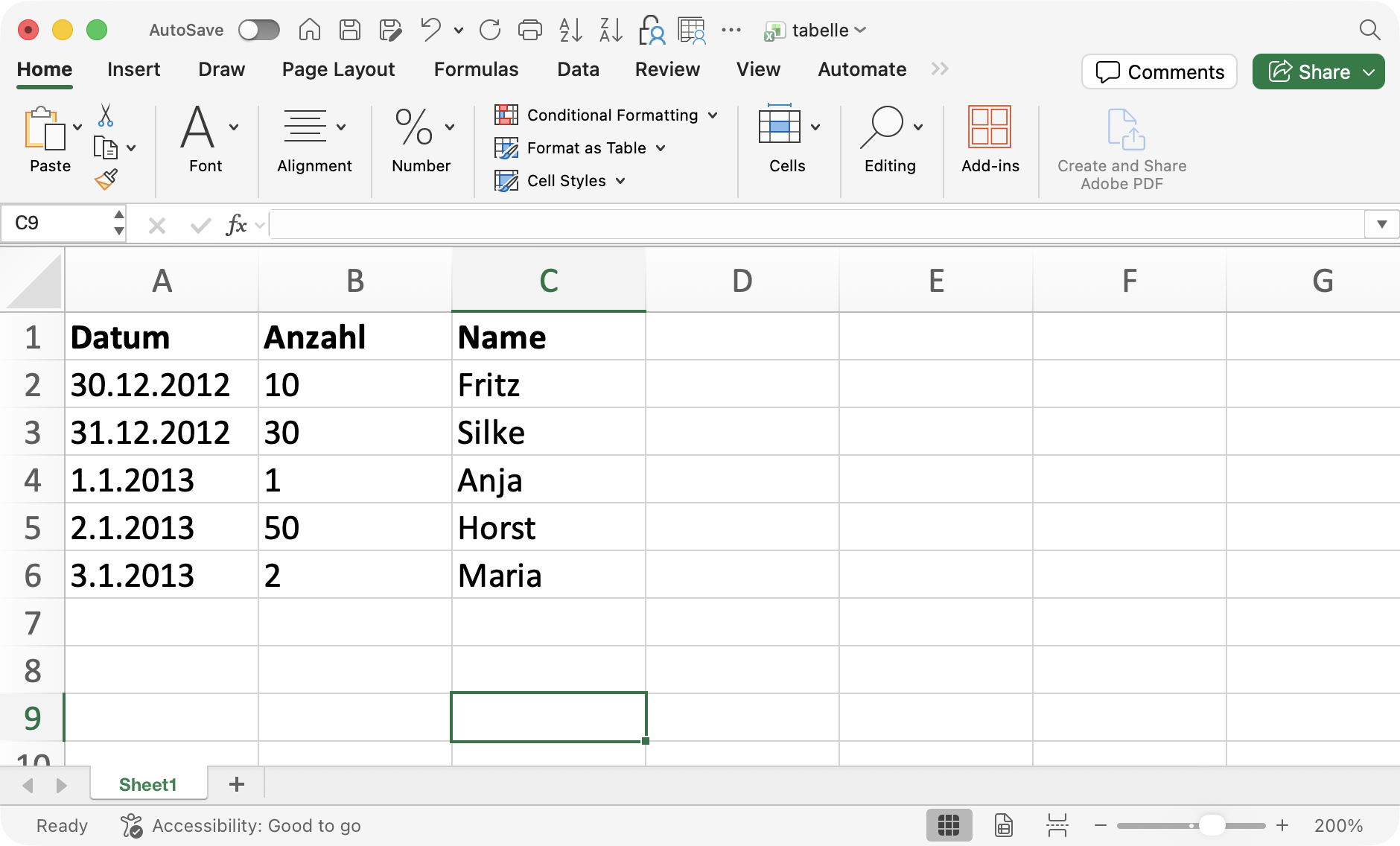
read_excel("daten/tabelle.xlsx")
read_excel(...)liest Excel-Datei und gibt Dataframe zurück- Im einfachsten Fall nur Datei angeben, Inhalt von erstem Tabellenblatt
- Datentypen der Spalten werden korrekt erkannt
Leider nicht immer so einfach

Wo liegt das Problem?
- Es soll bestimmtes Tabellenblatt gelesen werden
- Bereiche links und oben sollen ignoriert werden
→ Importassistent!
Importassistent 1/3

Importassistent 2/3

Importassistent 3/3
read_excel("daten/unistrasse-2017.xlsx", sheet = "raw(T)", range = "B2:H20712")- Einstellung in Excel unvollständig, daher Datum nicht richtig gelesen
10.3 CSV-Dateien einlesen
Aufbau und Inhalt von CSV-Dateien
- CSV: Comma Separated Values, weit verbreitet, nicht standardisiert
- Häufig Kopfzeile(n) mit Beschreibung des Inhalts
- Inhalt in der Regel mit
- Datenfeldern getrennt z.B. durch Komma, Semikolon, Leerzeichen…
- Datum in verschiedensten Formaten
- Zahlen mit oder ohne Dezimaltrenner (Punkt oder Komma)
- Spezielle Kennzeichnung von fehlenden Werten
Amerikanische Konvention
Datei beispiel-1.csv
A, B, C, D
1.2, 3, Frances, 2020-12-01
2.6, 1, Howard, 2020-12-01
1.7, 6, Kimberley, 2020-12-01
500000.2, 3, Stacey, 2020-12-01
- Einträge durch “
,” getrennt - Dezimaltrenner ist “
.” - Datum mit Jahr/Monat/Tag
Einlesen mit read_csv(...)
read_csv("daten/beispiel-1.csv")- Datentypen richtig erkannt
Deutsche Konvention
Datei beispiel-2.csv
A; B; C; D
1,2; 3; Franziska; 01-10-2022
2,6; 1; Philipp; 03-12-2002
1,7; 6; Angela; 29-01-1977
500.000,2; 3; Sabine; 07-01-1898
- Einträge durch “
;” getrennt - Dezimaltrenner “
,”, Tausender “.” - Datum mit Tag/Monat/Jahr
Einlesen mit read_csv2(...)
read_csv2("daten/beispiel-2.csv")- Datum nicht richtig erkannt
Gemischte Konvention
Datei beispiel-3.csv
A; B; C; D
1.2; 3; Franziska; 01-10-2022
2.6; 1; Philipp; 03-12-2002
1.7; 6; Angela; 29-01-1977
500,000.2; 3; Sabine; 07-01-1898
- Einträge durch “
;” getrennt - Dezimaltrenner “
.”, Tausender “,” - Datum mit Tag/Monat/Jahr
Einlesen mit read_delim(...)
read_delim("daten/beispiel-3.csv", delim = ";", trim_ws = TRUE, locale = locale(decimal_mark = ".", grouping_mark = ","))delim: Delimiter ist das Trennzeichenlocale: Länderspezifische Dingetrim_ws: Entfernt Leerzeichen- Datum nicht richtig erkannt
Kodierung
Datei beispiel-4.csv
A; B; C; D
1,2; 3; J�rg; 01-10-2022
2,6; 1; Clau�; 03-12-2002
1,7; 6; �ngela; 29-01-1977
500.000,2; 3; J�rgen; 07-01-1898
- Datei ISO-8859-1 kodiert
- Grundeinstellung in R ist UTF-8
- Sonst deutsche Konvention
Einlesen mit read_csv2(...)
read_csv2("daten/beispiel-4.csv", locale = locale(encoding = "iso-8859-1"))- Kodierung beim Einlesen angeben
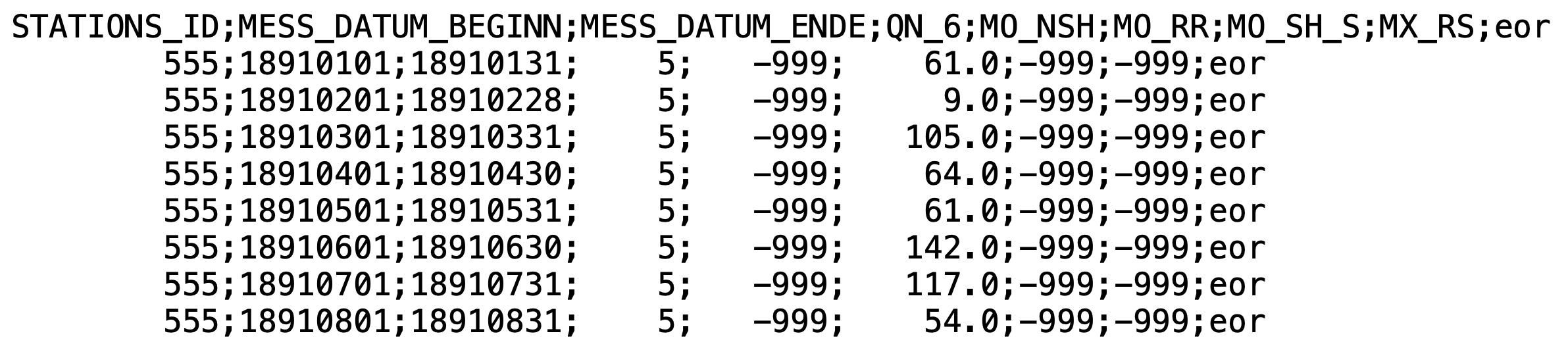
Beispiel: Niederschlagsdaten Bochum
read_delim(
"daten/produkt_nieder_monat_18910101_20171231_00555.txt",
delim = ";",
trim_ws = TRUE,
locale = locale(decimal_mark = ".", grouping_mark = ",")
)CSV-Dateien Zusammenfassung
Funktionen
read_csv(Dateiname, Argumente...) # Amerikanische Konvention
read_csv2(Dateiname, Argumente...) # Deutsche Konvention
read_delim(Dateiname, locale=locale(decimal_mark=".", grouping_mark=","), Argumente...)
Die wichtigsten Argumente
| Argument | Bedeutung | Optional |
|---|---|---|
skip = 5 |
Anzahl Zeilen, die überlesen werden sollten | Ja |
trim_ws = TRUE |
Leerzeichen entfernen (für read_delim) |
Ja |
show_col_types = FALSE |
Ausgabe unterdrücken | Ja |
10.4 Rohdaten
Hände weg von den Rohdaten!

Rohdaten nicht verändern
- Schwer nachvollziehbar
- Nicht rückgängig zu machen
- Schlimmstenfalls Datenverlust
Stattdessen
- Rohdaten unverändert einlesen
- In R aufbereiten
- R-Code dokumentiert Änderungen
→ Relevant für Benotung!
Beim Einlesen von Daten gilt immer
- In der Regel funktioniert es nicht auf Anhieb
- Eingelesene Daten sehr sorgfältig anschauen!
- Überblick verschaffen mit
summary(d)und/oderstr(d)