sin(sqrt(exp(1.5)))[1] 0.8545027“Happy families are all alike; every unhappy family is unhappy in its own way.” — Leo Tolstoy
“Tidy datasets are all alike, but every messy dataset is messy in its own way.” — Hadley Wickham
Tidy data (aufgeräumte Daten)
→ Nicht immer so eindeutig, wie es hier klingt
|>Mit geschachtelten Funktionen
sin(sqrt(exp(1.5)))[1] 0.8545027→ Zuerst wird \(e^{1.5}\) berechnet, dann die Wurzel gezogen und danach der Sinus ermittelt
Mit Pipe-Operator
1.5 |> exp() |> sqrt() |> sin()[1] 0.8545027→ Operator |> fügt linke Seite als erstes Argument der Funktion rechts ein

select() und rename()
d_uni <- read_excel("daten/unistrasse-2017-2.xlsx", sheet = "raw(T)", range = "B2:H20712")select()d_uni |> select(Datum, Geschwindigkeit, "Länge (cm)", Fahrzeug)select()d_uni |> select(-Fahrtrichtung, -Abstand, -"Länge (Radar)")- werden entferntselect()d_uni |> select(Datum, v = Geschwindigkeit, L = "Länge (cm)", Fahrzeug)neuer_name = alter_named <- tibble(A_X = 1:2, B_X = 3:4, C_X = 5:6, X_A = 7:8, X_B = 9:10, X_C = 11:12, ABC = 13:14)d |> select(starts_with("X_"))d |> select(ends_with("_X"))d |> select(-starts_with("X_"))d |> select(-ends_with("_X"))starts_with() und ends_with() Muster für Namen festlegen-rename()d_uni |> rename(v = Geschwindigkeit, laenge = "Länge (Radar)")neuer_name = alter_namefilter() und slice()
d <- d_uni |> select(Datum, Fahrzeug, Abstand, Geschwindigkeit)d |> filter(Fahrzeug == "LKW")d |> filter(Fahrzeug == "LKW" & Geschwindigkeit > 60)&d |> filter(Fahrzeug == "LKW" | Geschwindigkeit > 80)|d |> filter(is.na(Fahrzeug))NA entfernend |> filter(!is.na(Fahrzeug))d |> filter(Fahrzeug %in% c("Zweirad", "LKW"))slice()d |> slice(c(10, 30, 700))d |> slice_head(n = 10)d |> slice_tail(n = 10)n (Anzahl) Beobachtungen auswählenhead wie Kopf und tail wie Schwanz oder Ended |> slice_min(Geschwindigkeit, n = 10)d |> slice_max(Geschwindigkeit, n = 10)n (Anzahl) Beobachtungen auswählenmin wie Minimum und max wie Maximumarrange()
d |> arrange(Geschwindigkeit)d |> arrange(desc(Geschwindigkeit))desc() absteigend sortierend |> arrange(Fahrzeug, Geschwindigkeit)d |> arrange(Geschwindigkeit, Fahrzeug)mutate()
d |> mutate(V10 = signif(Geschwindigkeit, digits = 1))neue_variable = Ausdruck(alte_variablen)signif() auf eine signifikante Stellte gerundetd |> show()# A tibble: 20,710 × 4
Datum Fahrzeug Abstand Geschwindigkeit
<chr> <chr> <dbl> <dbl>
1 13.12.2017 00:03:31 PKW 262. 70
2 13.12.2017 00:03:37 PKW 5.18 59
3 13.12.2017 00:03:53 PKW 15.7 79
4 13.12.2017 00:05:42 PKW 111. 58
5 13.12.2017 00:06:51 PKW 69.5 60
6 13.12.2017 00:07:08 Transporter 16.7 57
7 13.12.2017 00:08:11 PKW 63.9 58
8 13.12.2017 00:09:41 PKW 90.7 54
9 13.12.2017 00:11:42 Transporter 122. 56
10 13.12.2017 00:17:31 PKW 354. 61
# ℹ 20,700 more rowsd |> mutate(Datum = dmy_hms(Datum, tz = "Europe/Berlin")) |> show()# A tibble: 20,710 × 4
Datum Fahrzeug Abstand Geschwindigkeit
<dttm> <chr> <dbl> <dbl>
1 2017-12-13 00:03:31 PKW 262. 70
2 2017-12-13 00:03:37 PKW 5.18 59
3 2017-12-13 00:03:53 PKW 15.7 79
4 2017-12-13 00:05:42 PKW 111. 58
5 2017-12-13 00:06:51 PKW 69.5 60
6 2017-12-13 00:07:08 Transporter 16.7 57
7 2017-12-13 00:08:11 PKW 63.9 58
8 2017-12-13 00:09:41 PKW 90.7 54
9 2017-12-13 00:11:42 Transporter 122. 56
10 2017-12-13 00:17:31 PKW 354. 61
# ℹ 20,700 more rowsdmy_hms(), ggf. Zeitzone angebend |>
mutate(
Datum = dmy_hms(Datum, tz = "Europe/Berlin"),
Uhrzeit = as_hms(Datum)
)as_hms() die Uhrzeit heraussuchen (library(hms))d |>
mutate(
Datum = dmy_hms(Datum, tz = "Europe/Berlin"),
D15 = floor_date(Datum, "15 minutes")
)floor_date(x, unit) rundet ab auf angegebene Einheitd_unistrasse <- read_excel("daten/unistrasse-2017-2.xlsx", sheet = "raw(T)", range = "B2:H20712") |>
select(Datum, Fahrzeug = Fahrzeug, L = `Länge (cm)`, v = Geschwindigkeit) |>
filter(!is.na(Fahrzeug)) |>
mutate(
Datum = dmy_hms(Datum, tz = "Europe/Berlin"),
D15 = floor_date(Datum, "15 minutes"),
Uhrzeit = as_hms(Datum)
)
d_unistrasseggplot(data = d_unistrasse) +
geom_hex(mapping = aes(x = Uhrzeit, y = v))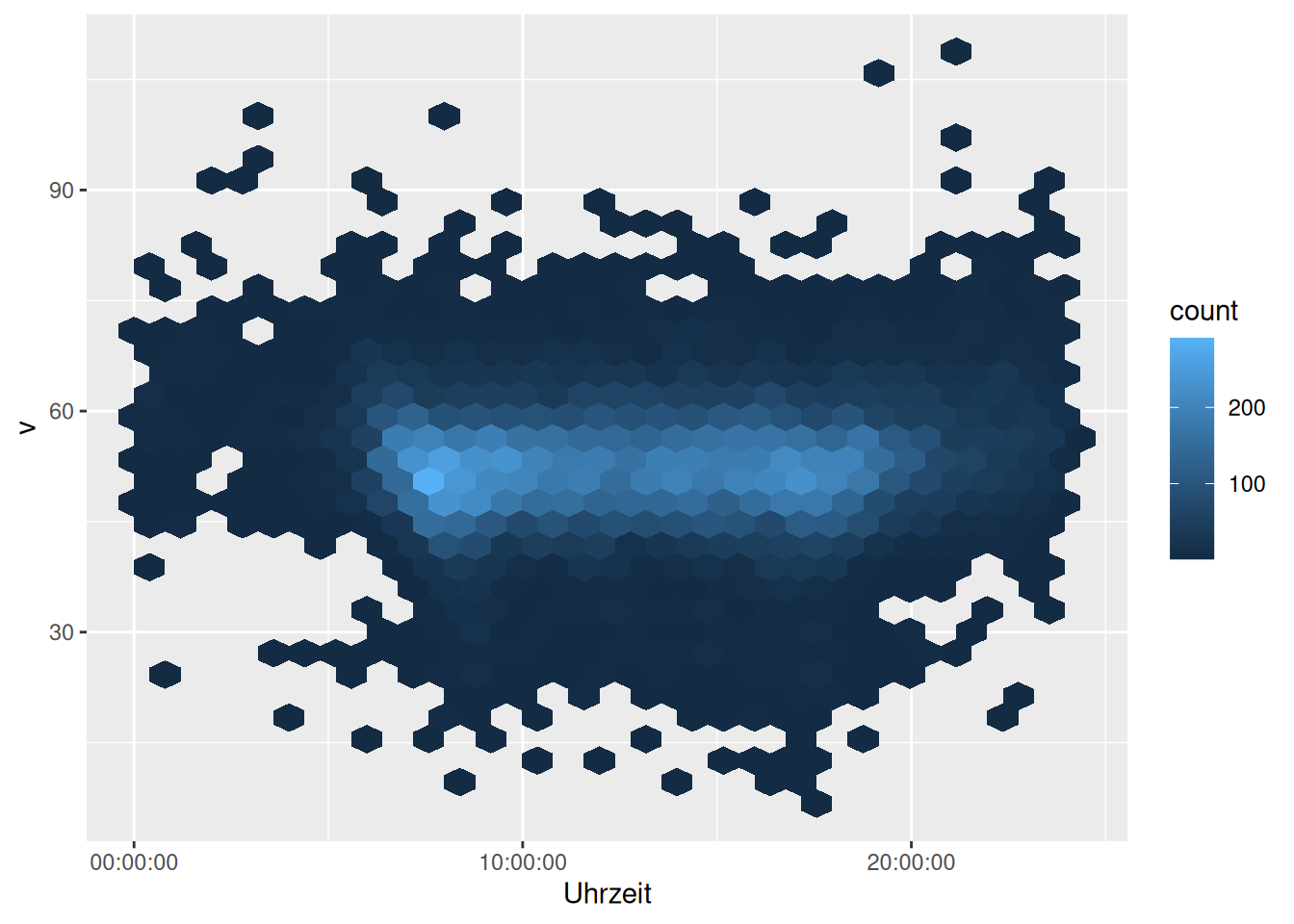
if_else()d |> mutate(Raser = if_else(Geschwindigkeit >= 70, "Ja", "Nein"))summarize() und group_by()
summarize()d_unistrasse |>
summarise(Anzahl = n(), Mittelwert = mean(v), Standardabweichung = sd(v))mutate(), aber Funktionen werden auf alle Werte angewendetn()mean() und sd() wie gehabt→ In dieser Form nicht besonders nützlich
group_by() und summarize()d_unistrasse |>
group_by(Fahrzeug) |>
summarise(Anzahl = n(), Mittelwert = mean(v), Standardabweichung = sd(v))group_by() nach Kriterium gruppierensummarize() zusammenfassen
summarize() werden auf Gruppen angewendet→ In Kombination sehr flexibel einsetzbar
d <- d_unistrasse |>
group_by(D15) |>
summarise(VMit = mean(v))
ggplot(data = d, mapping = aes(x = D15, y = VMit)) + geom_line() + geom_point()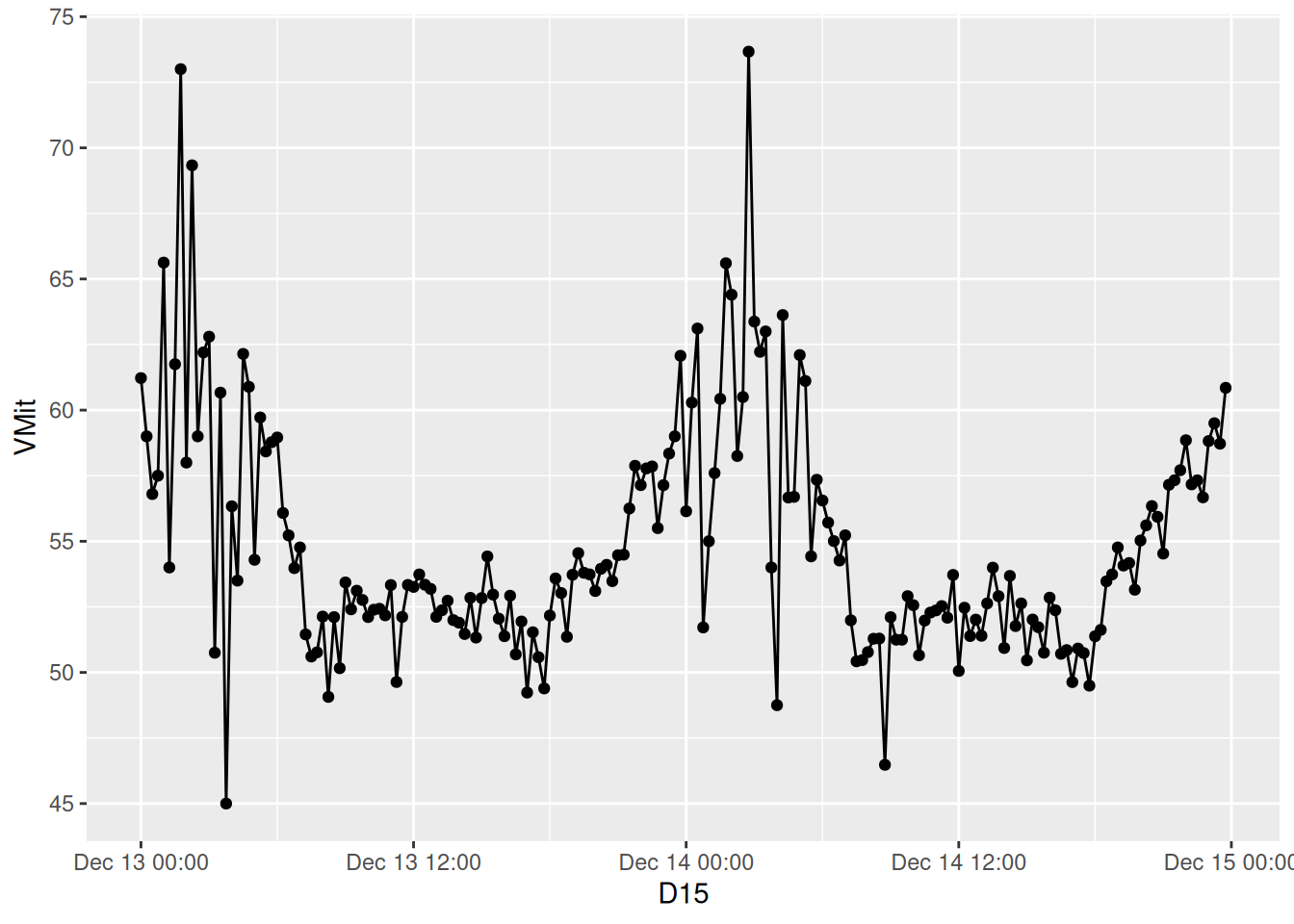
group_by()d_unistrasse |> str()tibble [20,707 × 6] (S3: tbl_df/tbl/data.frame)
$ Datum : POSIXct[1:20707], format: "2017-12-13 00:03:31" "2017-12-13 00:03:37" ...
$ Fahrzeug: chr [1:20707] "PKW" "PKW" "PKW" "PKW" ...
$ L : num [1:20707] 421 454 456 479 421 487 387 478 493 427 ...
$ v : num [1:20707] 70 59 79 58 60 57 58 54 56 61 ...
$ D15 : POSIXct[1:20707], format: "2017-12-13 00:00:00" "2017-12-13 00:00:00" ...
$ Uhrzeit : 'hms' num [1:20707] 00:03:31 00:03:37 00:03:53 00:05:42 ...
..- attr(*, "units")= chr "secs"group_by() - Attribute zur Gruppierungd_unistrasse |> group_by(Fahrzeug) |> str()gropd_df [20,707 × 6] (S3: grouped_df/tbl_df/tbl/data.frame)
$ Datum : POSIXct[1:20707], format: "2017-12-13 00:03:31" "2017-12-13 00:03:37" ...
$ Fahrzeug: chr [1:20707] "PKW" "PKW" "PKW" "PKW" ...
$ L : num [1:20707] 421 454 456 479 421 487 387 478 493 427 ...
$ v : num [1:20707] 70 59 79 58 60 57 58 54 56 61 ...
$ D15 : POSIXct[1:20707], format: "2017-12-13 00:00:00" "2017-12-13 00:00:00" ...
$ Uhrzeit : 'hms' num [1:20707] 00:03:31 00:03:37 00:03:53 00:05:42 ...
..- attr(*, "units")= chr "secs"
- attr(*, "groups")= tibble [5 × 2] (S3: tbl_df/tbl/data.frame)
..$ Fahrzeug: chr [1:5] "LKW" "Lastzug" "PKW" "Transporter" ...
..$ .rows : list<int> [1:5]
.. ..$ : int [1:2030] 11 34 62 68 103 115 121 153 155 161 ...
.. ..$ : int [1:813] 95 174 183 188 231 253 279 299 322 332 ...
.. ..$ : int [1:13995] 1 2 3 4 5 7 8 10 12 13 ...
.. ..$ : int [1:3709] 6 9 16 25 26 28 30 32 36 38 ...
.. ..$ : int [1:160] 63 72 154 258 662 691 895 898 991 1209 ...
.. ..@ ptype: int(0)
..- attr(*, ".drop")= logi TRUEpivot_longer() und pivot_wider()
pivot_longer(): Wenn Namen von Variablen Werte sein solltenpivot_wider(): Wenn Werte Namen von Variablen sein sollten→ Manchmal sind auch beide Varianten notwendig

→ Was man wirklich braucht hängt von der konkreten Situation ab

d_et_wide <- read_excel("daten/energiedaten-gesamt-xls.xlsx", sheet = "4", range = "A8:AC17")pivot_longer() 1/2d_et_wide |> pivot_longer(cols = "1990":"2017", names_to = "Jahr", values_to = "Verbrauch")1990 bis 2017 umordnennames_to = Name: Variable für alte Variablennamenvalues_to = Name: Variable für Wertepivot_longer() 2/2d_et_wide |> pivot_longer(cols = !Energieträger, names_to = "Jahr", values_to = "Verbrauch")Energieträger umordnennames_to = Name: Variable für alte Variablennamenvalues_to = Name: Variable für Werted_et_long <-
read_excel("daten/energiedaten-gesamt-xls.xlsx", sheet = "4", range = "A8:AC17") |>
pivot_longer(!Energieträger, names_to = "Jahr", values_to = "Verbrauch") |>
mutate(Jahr = as.numeric(Jahr))
ggplot(data = d_et_long) +
geom_line(mapping = aes(x = Jahr, y = Verbrauch, color = Energieträger))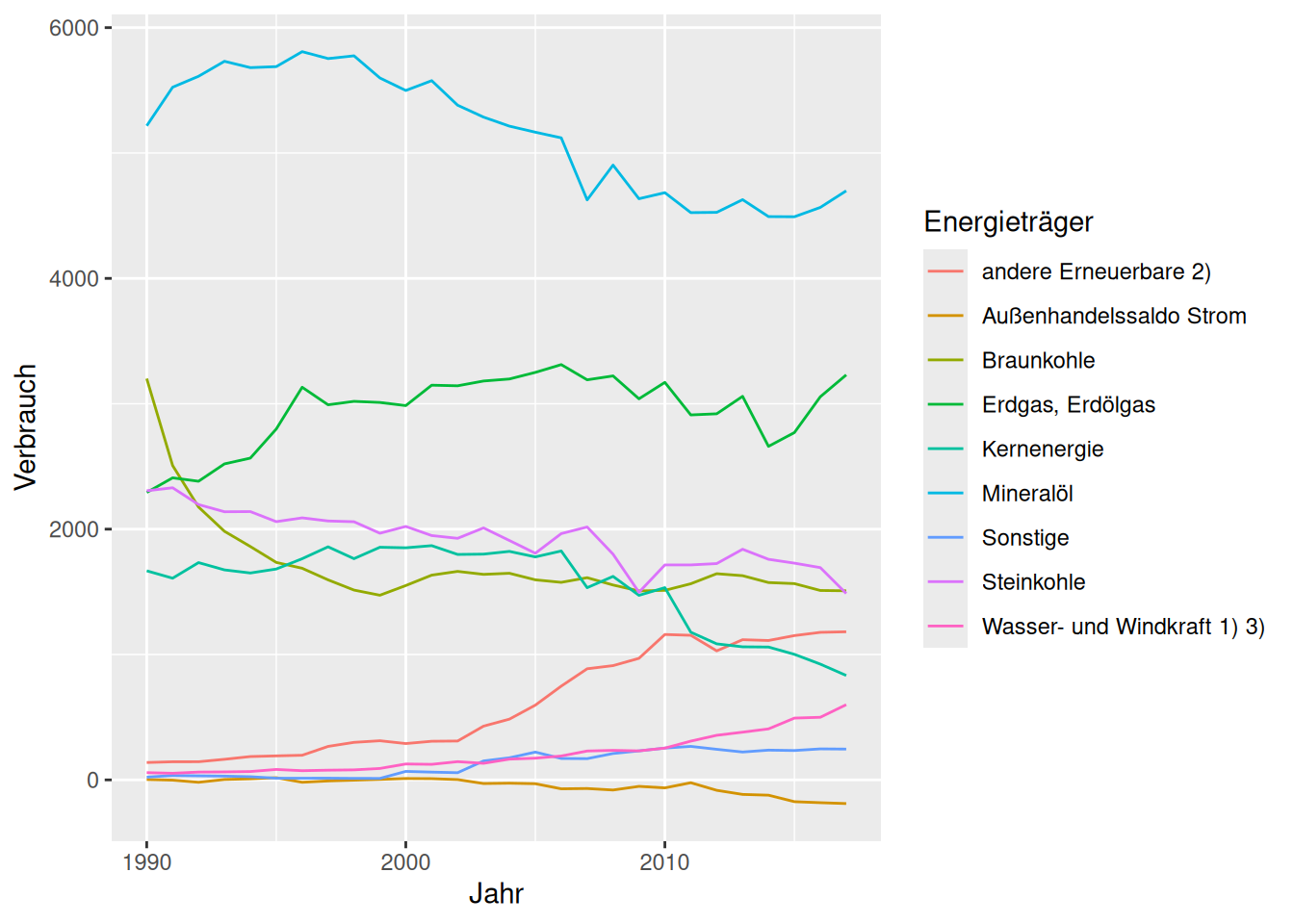
mutate()pivot_wider()d_et_long |> pivot_wider(names_from = Energieträger, values_from = Verbrauch)names_from = Name: Variable mit neuen Variablennamenvalues_from = Name: Variable mit Werten, die verteilt werden sollenleft_join()

d_mitarbeitende <- read_excel("daten/mitarbeitende-beispiel.xlsx", range = "B2:E7")d_abteilungen <- read_excel("daten/mitarbeitende-beispiel.xlsx", range = "G2:I7")left_join()d_mitarbeitende |> left_join(d_abteilungen)rename() umbenennen (wie select())left_join(): Alle Zeilen aus linker Tabelle werden übernommeninner_join() etc.) für Spezialfälleleft_join unterdrücken mit #| message: false
d_ud <- read_excel("daten/beispiel-kodierung.xlsx", range = "B2:D5")
d_ud_k1 <- read_excel("daten/beispiel-kodierung.xlsx", range = "F2:G5")d_ud_k2 <- read_excel("daten/beispiel-kodierung.xlsx", range = "I2:J5")d_ud |>
left_join(d_ud_k1) |>
left_join(d_ud_k2) |>
select(-ends_with("_code"))bind_rows()/bind_cols()d1 <- tibble(X = c("A", "B"), Y = c(1, 2))
d2 <- tibble(Y = c(3, 1), Z = c(98, 99))d1d2d1 |> bind_cols(d2)...d1 |> bind_rows(d2)NA
Niederschlagsdaten vom Deutschen Wetterdienst
NA seind_ns <- read_delim(
"daten/produkt_nieder_monat_18910101_20171231_00555.txt",
delim = ";", , trim_ws = TRUE, locale = locale(decimal_mark = ".", grouping_mark = ",")
)d_ns |>
mutate(
MO_NSH = na_if(MO_NSH, -999)
)na_if(Y, x) alle Werte x in Variable Y durch NA ersetzend_ns |>
mutate(
across(c(MO_NSH, MO_RR, MO_SH_S, MX_RS), ~na_if(.x, -999))
)across die Formel ~na_if(., -999) auf mehrere Variablen anwendend_z <- tibble(X = c("10, A, 4.3", "11, X, 1.9", "2, R, 3.3"))d_z |> separate(X, c("Wert", "Name", "Laenge"))separate(...) verteilt Werte auf Variablenmutate() 1/3d_et_longmutate() 2/3d <- d_et_long |>
group_by(Jahr) |>
mutate(Anteil = 100 * Verbrauch / sum(Verbrauch))sum() die Summe in einer Gruppe berechnenmutate() 3/3d |>
filter(Jahr == 2000)slice() 1/2d_unistrasseslice() 2/2d_unistrasse |> select(-D15) |>
group_by(Fahrzeug) |>
slice_max(v, n = 1) |> ungroup()slice_max(v, n = 1) schnellstes Fahrzeug heraussuchensummarize()recode() 1/2d_et_widerecode() 2/3d_et_wide |>
mutate(
Energieträger = replace_values(
Energieträger,
"Erdgas, Erdölgas" ~ "Gas",
"Wasser- und Windkraft 1) 3)" ~ "Wasser/Wind",
"andere Erneuerbare 2)" ~ "andere Erneuerbare"
)
)"Alter Wert" ~ "Neuer Wert"recode() 3/3alt <- c("Erdgas, Erdölgas", "Wasser- und Windkraft 1) 3)", "andere Erneuerbare 2)")
neu <- c("Gas", "Wasser/Wind", "andere Erneuerbare")
d_et_wide |>
mutate(
Energieträger = replace_values(
Energieträger, from = alt, to = neu
)
)