d <- tibble(A = c(1, 2, 3), B = c("u", "v", "w"))
save(d, file = "daten/test.RData")
rm(list = "d")14 Tipps und Tricks
14.1 Dataframes speichern und laden
Dataframe speichern und laden 1/3
Manchmal dauert es lange einen bestimmten Dataframe zu erzeugen. Dies kann zum Beispiel der Fall sein, wenn die Daten zuerst aus dem Internet heruntergeladen werden müssen. Dann macht es oft Sinn, das Projekt in zwei Dateien aufzuteilen:
In der einen qmd-Datei werden die Daten geladen und aufbereitet. Die fertigen Daten können dann auf der Festplatte abgelegt werden.
In einer anderen qmd-Datei werden die aufbereiteten Daten von der Festplatte eingelesen und dann statistisch ausgewertet.
Diese Vorgehensweise lässt sich mit wenig Aufwand durch die Funktionen save und load realisieren.
Dataframe speichern und laden 2/3
Dataframe d
- anlegen
- in der Datei
daten/test.RDataspeichern - löschen (nur für Demonstrationszwecke)
Dataframe speichern und laden 3/3
load("daten/test.RData")
d- Dataframe
dwurde aus der Datei geladen und ist jetzt wieder vorhanden - Einlesen geht auch für umfangreiche Datensätze sehr schnell
14.2 Zeichenketten suchen und ersetzen
Beispieldatensatz
d <- tibble(
Name = c("unistrasse_nord", "unistrasse_sued", "markstrasse_ost", "markstrasse_west"),
Wert = c(10, 20, 4, 8)
)
dRichtung löschen
d |>
mutate(NameKurz = str_replace(Name, "_nord|_sued|_ost|_west", ""))- Mit
str_replaceRichtungen durch eine leere Zeichenkette ersetzen - Verschiedene zu ersetztende Zeichenketten mit
|trennen
14.3 Daten mit sehr vielen Merkmalen und/oder kryptischen und/oder langen Namen für Spalten
Beispieldatensatz
d <- read_csv2("daten/Jawe2020.csv", locale = locale(encoding = "ISO-8859-1"))
d- Daten zu Dauerzählstellen von der Bast
- Tabelle mit 235 Spalten
- Idee: Auswahl und Benennung der Spalten in Excel-Tabelle
Schritt 1: Tabelle anlegen und in Excel bearbeiten
colnames(d) |>
as_tibble_col(column_name = "name_alt") |>
write_csv("daten/jawe-spalten.csv")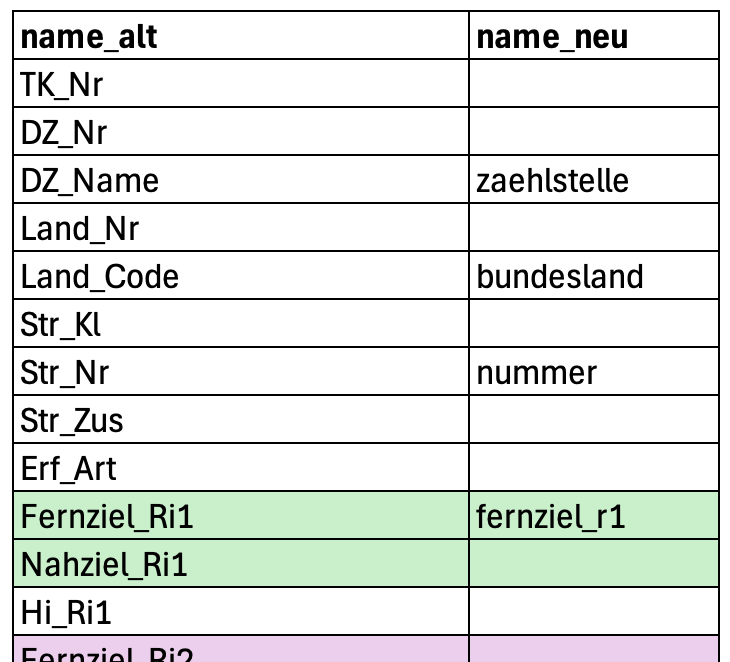
jawe-spalten.csvin Excel öffnen- Spalten benennen
- Als Excel-Dokument speichern
Schritt 2: Namen einlesen und umbenennen
colnames <- read_excel("daten/jawe-spalten.xlsx") |>
filter(!is.na(name_neu)) |>
select(name_neu, name_alt) |>
deframe()
d1 <- d |> select(all_of(colnames))- Namen der Spalten
- Tabelle einlesen
- Zeilen mit neuem Namen
- Spalten anordnen
- Mit
deframein named vector konvertieren
- Dataframe
- Spalten aus
colnames
- Spalten aus
14.4 Namen von Spalten enthalten Merkmale und Werte
Beispieldatensatz
d_f <- read_excel("daten/familien-1.xlsx")
d_f- Unhandlich
- Ziel: Tabelle mit einer Zeile je Kind
Schritt 1: Alles in eine Zeile
d1 <- d_f |>
pivot_longer(
cols = starts_with("kind"), values_transform = as.character, values_drop_na = TRUE
)- Alle Spalten, die mit “kind” anfangen auswählen
- Name der Spalte wird Merkmal ‘name’
- Wert wird Merkmal ‘value’
- Einträge in Zeichenketten konvertieren
- nur falls unterschiedliche Werte
- Zeilen ohne Werte wegwerfen
Schritt 2: Spalten für Kind und Merkmal
d2 <- d1 |>
separate(name, into = c(NA, "kind", "merkmal"))- Inhalt von Variable
namein Variablenkindundmerkmalaufteilen - Nicht benögte Spalte mit
NA
Schritt 3: Spalten für Merkmale
d3 <- d2 |>
pivot_wider(names_from = merkmal, values_from = value) |>
mutate(alter = as.integer(alter))- Aus Inhalt der Spalte
Merkmalwerden Namen von Spalten - Werte aus Spalte
valueeinsetzen Alterwieder in Zahl umwandeln (optional)
In einem Rutsch
d_k <- d_f |>
pivot_longer(
cols = starts_with("kind"), values_transform = as.character, values_drop_na = TRUE
) |>
separate(name, into = c(NA, "kind", "merkmal")) |>
pivot_wider(names_from = merkmal, values_from = value) |>
mutate(Alter = as.integer(alter))In einem Rutsch
d_k14.5 Namen von Spalten enthalten Merkmale und es gibt Defaultwerte
Beispieldatensatz
d_f <- read_excel("daten/familien-2.xlsx")- Unhandlich
- Ziel: Tabelle mit einer Zeile je Kind
- Werte aus Spalte
Schule alle Kinderübernehmen
Schritt 1: Alles in eine Zeile
d1 <- d_f |>
pivot_longer(cols = starts_with("kind"), values_to = "schule")- Alle Variablen mit
"kind"
Schritt 2: Spalte für Kind
d2 <- d1 |>
separate(name, into = c(NA, "kind", NA)) |> mutate(kind = as.integer(kind))- Von den neuen Spalten nur
kindbehalten - In Zahl umwandeln
Schritt 3: Defaultwert raussuchen
d3 <- d2 |>
mutate(
schule = if_else(is.na(schule) & kind <= anzahl_kinder, schule_alle_kinder, schule)
) |>
filter(!is.na(schule)) |>
select(-schule_alle_kinder, -anzahl_kinder)- Defaultwert übernehmen, falls
- kein Wert für Schule
- Nummer des Kindes kleiner gleich Anzahl Kinder
- Ansonsten alten Wert beibehalten
- Zeilen ohne Schule löschen
In einem Rutsch
d_k <- d_f |>
pivot_longer(cols = starts_with("kind"), values_to = "schule") |>
separate(name, into = c(NA, "kind", NA)) |>
mutate(Kind = as.integer(kind)) |>
mutate(
schule = if_else(
is.na(schule) & kind <= anzahl_kinder, schule_alle_kinder, schule
)
) |>
filter(!is.na(schule)) |>
select(-schule_alle_kinder, -anzahl_kinder)In einem Rutsch
d_k