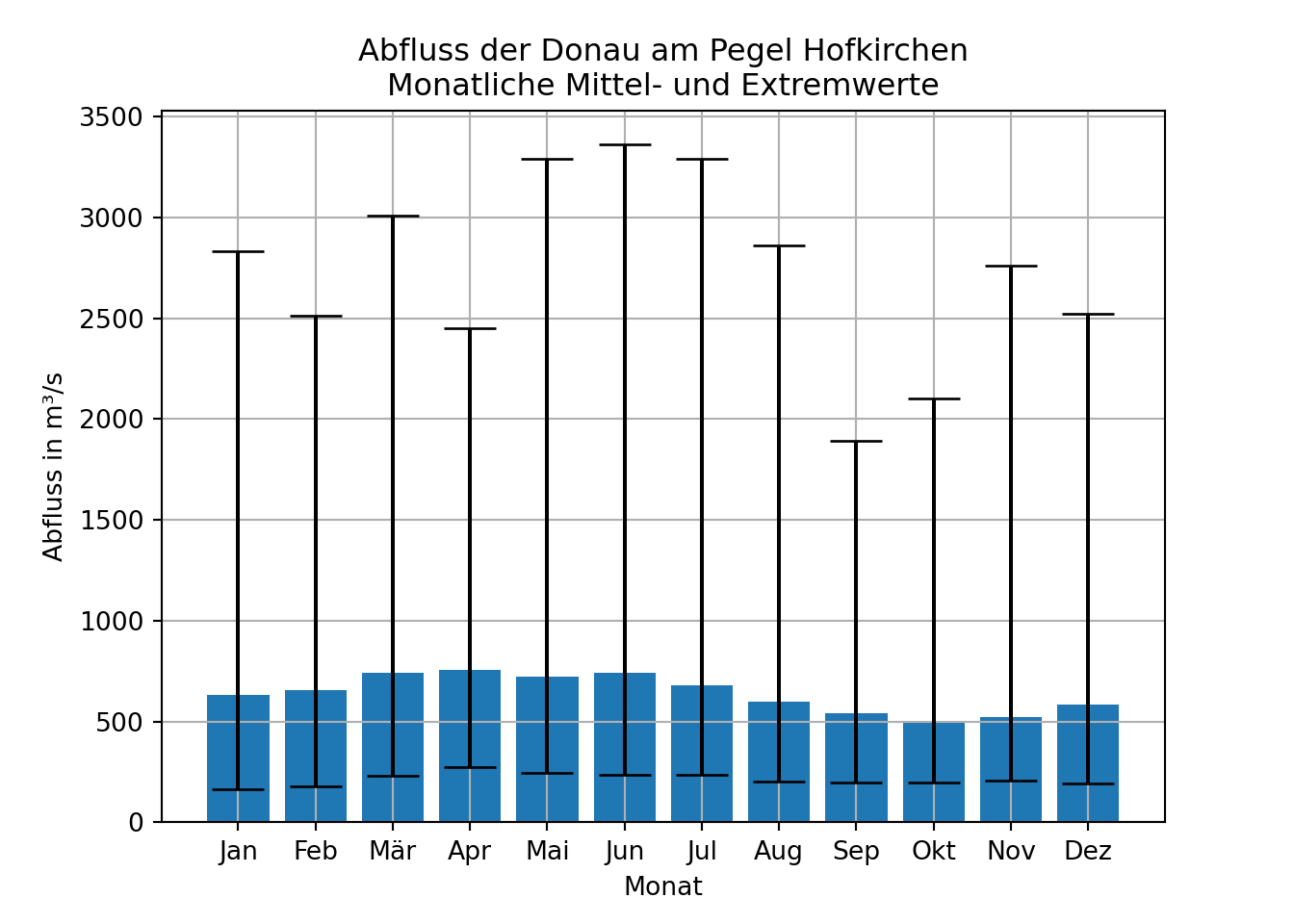
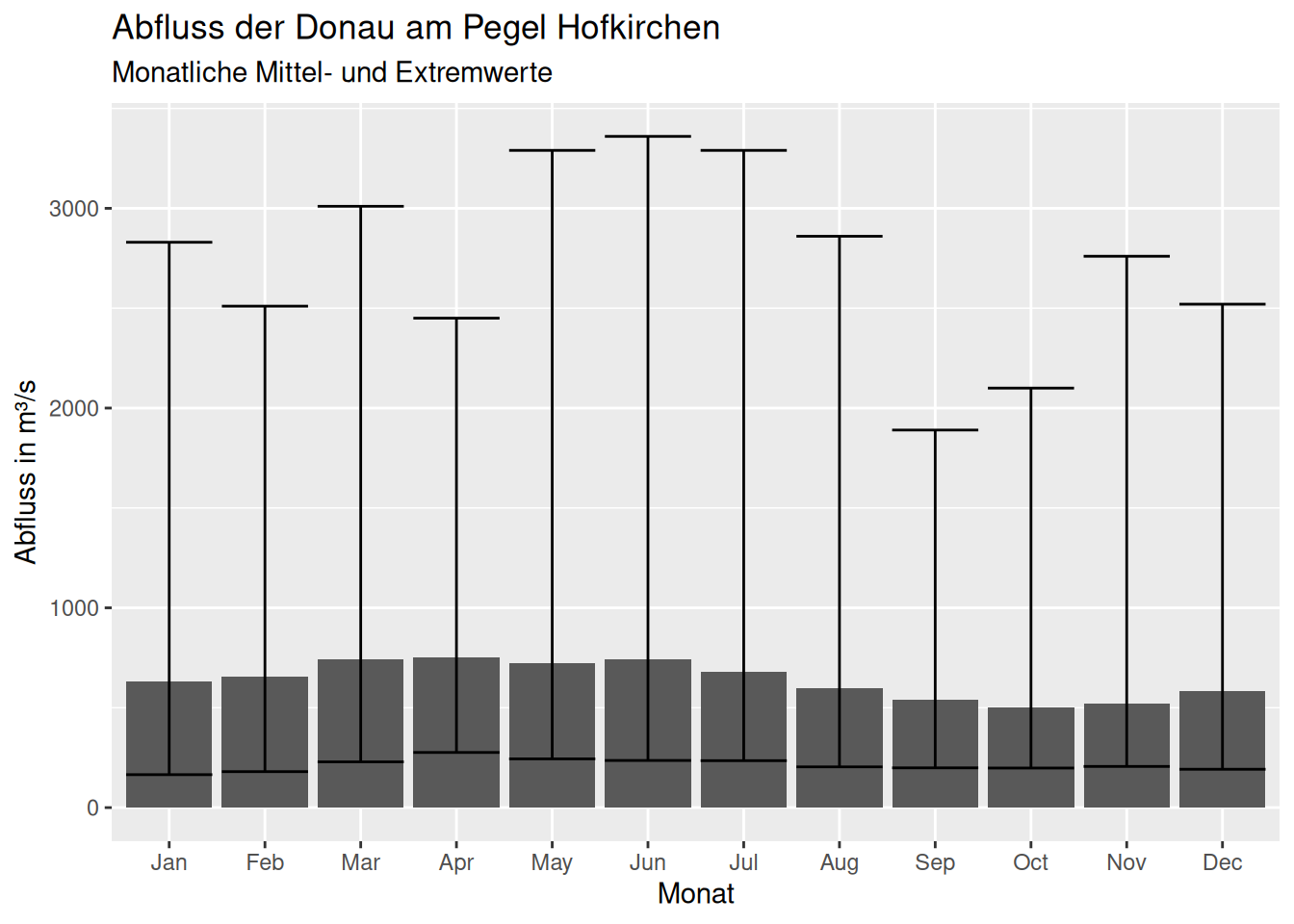
Im Rahmen des Moduls “Mathematik B” werden Sie grundlegende Methoden der Statistik auf konkrete Datensätze aus verschiedenen Bereichen des Bau- und Umweltingenieurwesens anwenden. Dies ist ohne die Anwendung von Computern nicht sinnvoll möglich.
Zur Bearbeitung von Aufgaben aus dem Bereich der Stochastik und Statistik eignen sich prinzipiell eine Vielzahl verschiedener Programme.
- Tabellenkalkulation:
-
Bis zu einem gewissen Grad lässt sich Statistik auch mit gängigen Tabellenkalkulationsprogrammen wie Excel oder Numbers betreiben (siehe zum Beispiel Matthäus und Matthäus (2016)). Allerdings sind viele konkrete Aufgaben aus der Statistik mit Tabellenkalkulationsprogrammen nur sehr umständlich und zeitraubend zu lösen, insbesondere wenn es sich um umfangreiche Datensätze handelt.
- SPSS:
-
Das Programm SPSS (Statistical Package for the Social Sciences) ist insbesondere in den Sozialwissenschaften und der Medizin verbreitet. Es erlaubt die Analyse von Daten in einer komfortablen grafischen Oberfläche. Allerdings ist es in den Ingenieurwissenschaften nicht weit verbreitet, in der Anwendung eher unflexibel und, nicht zuletzt, sehr teuer.
- Programmiersprache Python:
-
Python ist eine allgemein einsetzbare Programmiersprache, die sich in den letzten Jahren auch im Bereich der Datenanalyse und Statistik etabliert hat. Mit Bibliotheken wie NumPy, pandas, matplotlib und scikit-learn lassen sich statistische Auswertungen, Datenvisualisierungen und maschinelles Lernen umsetzen. Python ist Open Source, plattformunabhängig und wird in vielen wissenschaftlichen und technischen Disziplinen eingesetzt.
- Programmiersprache R:
-
In der Datenanalyse hat sich die Programmiersprache R, die häufig zusammen mit der Entwicklungsumgebung RStudio eingesetzt wird, fest etabliert. R ist speziell auf die Anforderungen der Statistik zugeschnitten und mit dem tidyverse existiert eine umfassende Sammlung von Bibliotheken. RStudio ist eine komfortable grafische Oberfläche, in der statistische Auswertungen in R durchgeführt werden können. Sowohl R als auch RStudio sind plattformunabhängig und Open Source.
Für unsere Zwecke kommen Tabellenkalkulationsprogramme und SPSS aus mehreren Gründen nicht infrage. Demgegenüber sind sowohl Python als auch R grundsätzlich geeignet, wobei beide Programmiersprachen ihre spezifischen Vor- und Nachteile haben. Hier ein kleiner Vergleich, der zeigt, wie eine Aufgabe in beiden Umgebungen umgesetzt werden kann.
Wichtig ist dabei, dass es sich bei Mathematik B ausdrücklich nicht um ein Informatikmodul handelt. Sie werden nicht im klassischen Sinne programmieren (Schleifen, Verzweigungen), im Vordergrund stehen vielmehr die Aufbereitung und Auswertung realer Datensätze.
Fahrmeir, Ludwig, Christian Heumann, Rita Künstler, Iris Pigeot, und Gerhard Tutz. 2016. Statistik, Der Weg zur Datenanalyse. 8. Auflage. Springer Spektrum.
Kueres, Dominik, Carsten Siburg, Martin Herbrand, Martin Claßen, und Josef Hegger. 2016. „Einheitliches Bemessungsmodell gegen Durchstanzen in Flachdecken und Fundamenten“. Beton- und Stahlbetonbau 111 (1): 9–19.
Matthäus, Heidrun, und Wolf-Gert Matthäus. 2016. Statistik und Excel. Springer Fachmedien.