pfad_maya = "01-daten/dice-maya.txt"
pfad_hans = "01-daten/dice-hans.txt"7 Dateien lesen und schreiben
Maya und Hans haben je sechs Mal einen Würfel geworfen und ihre Wurfergebnisse in einer .txt-Datei protokolliert. Wir wollen die Dateien mit Python auswerten, um zu bestimmen, wer von beiden in Summe die höchste Augenzahl erreicht hat.
| Daten | Dateiname |
|---|---|
| Würfelergebnisse Maya | dice-maya.txt |
| Würfelergebnisse Hans | dice-hans.txt |
7.1 Dateiobjekte
Um mit Python auf eine Datei zuzugreifen, muss diese fürs Lesen oder Schreiben geöffnet werden. Dazu wird in Python die Funktion open verwendet. Diese nimmt zwei Argumente, den Pfad der Datei und den Zugriffsmodus, an und liefert ein Dateiobjekt zurück. Aus dem Dateiobjekt werden dann die Inhalte der Datei ausgelesen.
Dateipfad
Der lokale Dateipfad wird ausgehend vom aktuellen Arbeitsverzeichnis angegeben.
Tipp 7.1: Arbeitsverzeichnis in Python ermitteln und wechseln
Der Pfad des aktuellen Arbeitsverzeichnisses kann mit dem Modul os mittels os.getcwd() ermittelt werden (hier ohne Ausgabe). Mit os.chdir('neuer_pfad') kann das Arbeitsverzeichnis ggf. gewechselt werden. Die korrekte Formatierung des Pfads erkennen Sie an der Ausgabe von os.getcwd().
import os
print(os.getcwd())Das Importieren von Modulen wird in einem späteren Kapitel behandelt.
Zugriffsmodus
Als Zugriffsmodus stehen unter anderem folgende Optionen zur Verfügung:
| Modus | Beschreibung |
|---|---|
r |
lesender Zugriff |
w |
Schreibzugriff, Datei wird überschrieben |
x |
Erzeugt die Datei, Fehlermeldung, wenn die Datei bereits existiert |
a |
Schreibzugriff, Inhalte werden angehängt |
b |
Binärmodus (z. B. für Grafiken) |
t |
Textmodus, default |
Die Zugriffsmodi können auch kombiniert werden. Weitere Informationen dazu finden Sie in der Dokumentation. Sofern nicht im Binärmodus auf Dateien zugegriffen wird, liefert die Funktion open() den Dateiinhalt als string zurück.
Im Lesemodus wird ein Datenobjekt erzeugt.
daten_maya = open(pfad_maya, mode = 'r')
print(daten_maya)<_io.TextIOWrapper name='01-daten/dice-maya.txt' mode='r' encoding='UTF-8'>Wenn das Datenobjekt daten_maya der Funktion print() übergeben wird, gibt Python die Klasse des Objekts zurück, in diesem Fall also _io.TextIOWrapper. Diese Klasse stammt aus dem Modul io und ist für das Lesen und Schreiben von Textdateien zuständig. Ebenfalls werden als Attribute des Dateiobjekts der Dateipfad, der Zugriffsmodus und die Enkodierung der Datei ausgegeben (siehe Beispiel 7.1). Sollte die Enkodierung nicht automatisch als UTF-8 erkannt werden, kann diese mit dem Argument encoding = 'UTF-8' übergeben werden.
daten_maya = open(pfad_maya, mode = 'r', encoding = 'UTF-8')
print(daten_maya)<_io.TextIOWrapper name='01-daten/dice-maya.txt' mode='r' encoding='UTF-8'>
Beispiel 7.1: Attribute eines Objekts bestimmen
Mit der Funktion dir(objekt) können die verfügbaren Attribute eines Objekts ausgegeben werden. Dabei werden jedoch auch die vererbten Attribute und Methoden der Klasse des Objekts ausgegeben, sodass die Ausgabe oft sehr umfangreich ist. Zum Beispiel für die Ganzzahl 1:
print(dir(1))['__abs__', '__add__', '__and__', '__bool__', '__ceil__', '__class__', '__delattr__', '__dir__', '__divmod__', '__doc__', '__eq__', '__float__', '__floor__', '__floordiv__', '__format__', '__ge__', '__getattribute__', '__getnewargs__', '__getstate__', '__gt__', '__hash__', '__index__', '__init__', '__init_subclass__', '__int__', '__invert__', '__le__', '__lshift__', '__lt__', '__mod__', '__mul__', '__ne__', '__neg__', '__new__', '__or__', '__pos__', '__pow__', '__radd__', '__rand__', '__rdivmod__', '__reduce__', '__reduce_ex__', '__repr__', '__rfloordiv__', '__rlshift__', '__rmod__', '__rmul__', '__ror__', '__round__', '__rpow__', '__rrshift__', '__rshift__', '__rsub__', '__rtruediv__', '__rxor__', '__setattr__', '__sizeof__', '__str__', '__sub__', '__subclasshook__', '__truediv__', '__trunc__', '__xor__', 'as_integer_ratio', 'bit_count', 'bit_length', 'conjugate', 'denominator', 'from_bytes', 'imag', 'is_integer', 'numerator', 'real', 'to_bytes']Um die Ausgabe auf Attribute einzugrenzen, kann folgende Funktion verwendet werden:
objekt = 1
attribute = [attr for attr in dir(objekt) if not callable (getattr(objekt, attr))]
print(attribute)['__doc__', 'denominator', 'imag', 'numerator', 'real']Mit doppelten Unterstrichen umschlossene Attribute sind für Python reserviert und nicht für den:die Nutzer:in gedacht. Folgende Funktion entfernt Attribute mit doppelten Unterstrichen aus der Ausgabe:
objekt = 1
attribute = [attr for attr in dir(objekt) if not (callable(getattr(objekt, attr)) or attr.startswith('__'))]
print(attribute)['denominator', 'imag', 'numerator', 'real']Im Fall einer Ganzzahl können Attribute (zur Abgrenzung von Gleitkommazahlen in umschließenden Klammern) wie folgt aufgerufen werden:
(1).numerator1Wenn wir uns die Attribute des Dateiobjekts ‘daten_maya’ ansehen, fallen Attribute mit einem einzelnen führenden Unterstrich auf.
objekt = daten_maya
attribute = [attr for attr in dir(objekt) if not (callable(getattr(objekt, attr)) or attr.startswith('__'))]
print(attribute)['_CHUNK_SIZE', '_finalizing', 'buffer', 'closed', 'encoding', 'errors', 'line_buffering', 'mode', 'name', 'newlines', 'write_through']Hierbei handelt es sich um Attribute, die nicht durch den:die Nutzer:in aufgerufen werden sollen (weitere Informationen dazu finden Sie hier). Folgender Programmcode gibt alle Attribute ohne führende Unterstriche aus:
objekt = daten_maya
attribute = [attr for attr in dir(objekt) if not (callable(getattr(objekt, attr)) or attr.startswith('_'))]
print(attribute)['buffer', 'closed', 'encoding', 'errors', 'line_buffering', 'mode', 'name', 'newlines', 'write_through']Die Attribute der Datei können mit entsprechenden Befehlen abgerufen werden.
print(f"Dateipfad: {daten_maya.name}\n"
f"Dateiname: {os.path.basename(daten_maya.name)}\n"
f"Datei ist geschlossen: {daten_maya.closed}\n"
f"Zugriffsmodus: {daten_maya.mode}\n"
f"Enkodierung: {daten_maya.encoding}")Dateipfad: 01-daten/dice-maya.txt
Dateiname: dice-maya.txt
Datei ist geschlossen: False
Zugriffsmodus: r
Enkodierung: UTF-8
Tipp 7.2: Rückfalloption
In der Datenanalyse werden in der Regel spezialisierte Pakete wie NumPy oder Pandas verwendet. Diese vereinfachen das Einlesen von Dateien gegenüber der Pythonbasis erheblich. Dennoch ist es sinnvoll, sich mit den Methoden der Pythonbasis zum Einlesen von Dateien vertraut zu machen. Denn das Einlesen mit der Funktion open() klappt so gut wie immer - es ist eine gute Rückfalloption.
Dateiinhalt ausgeben
Um den Dateiinhalt auszugeben, kann das Datenobjekt mit einer Schleife zeilenweise durchlaufen und ausgegeben werden. (Die Datei dice-maya hat nur eine Zeile.)
i = 0
for zeile in daten_maya:
print(f"Inhalt Zeile {i}, mit {len(zeile)} Zeichen:")
print(zeile)
i += 1Inhalt Zeile 0, mit 28 Zeichen:
"5", "6", "2", "1", "4", "5"Dies ist jedoch für größere Dateien nicht sonderlich praktikabel. Die Ausgabe einzelner Zeilen mit der Funktion print() kann aber nützlich sein, um die genaue Formatierung der Zeichenkette zu prüfen. In diesem Fall hat Maya ihre Daten in Anführungszeichen gesetzt und mit einem Komma voneinander getrennt.
7.2 Dateien einlesen
Um den gesamten Inhalt einer Datei einzulesen, kann die Methode datenobjekt.read() verwendet werden. Die Methode hat als optionalen Parameter .read(size). size wird als Ganzzahl übergeben und entsprechend viele Zeichen (im Binärmodus entsprechend viele Bytes) werden ggf. bis zum Dateiende ausgelesen. Der Parameter size ist nützlich, um die Formatierung des Inhalts einer großen Datei zu prüfen und dabei die Ausgabe auf eine überschaubare Anzahl von Zeichen zu begrenzen.
augen_maya = daten_maya.read()
print(f"len(augen_maya): {len(augen_maya)}\n\n"
f"Inhalt der Datei augen_maya:\n{augen_maya}")len(augen_maya): 0
Inhalt der Datei augen_maya:
Das hat offensichtlich nicht geklappt, der ausgelesene Dateiinhalt ist leer! Der Grund dafür ist, dass beim Lesen (und beim Schreiben) einer Datei der Dateizeiger die Datei durchläuft. Nachdem die Datei daten_maya in Kapitel 7.1.3 zeilenweise ausgegeben wurde, steht der Dateizeiger am Ende der Datei.
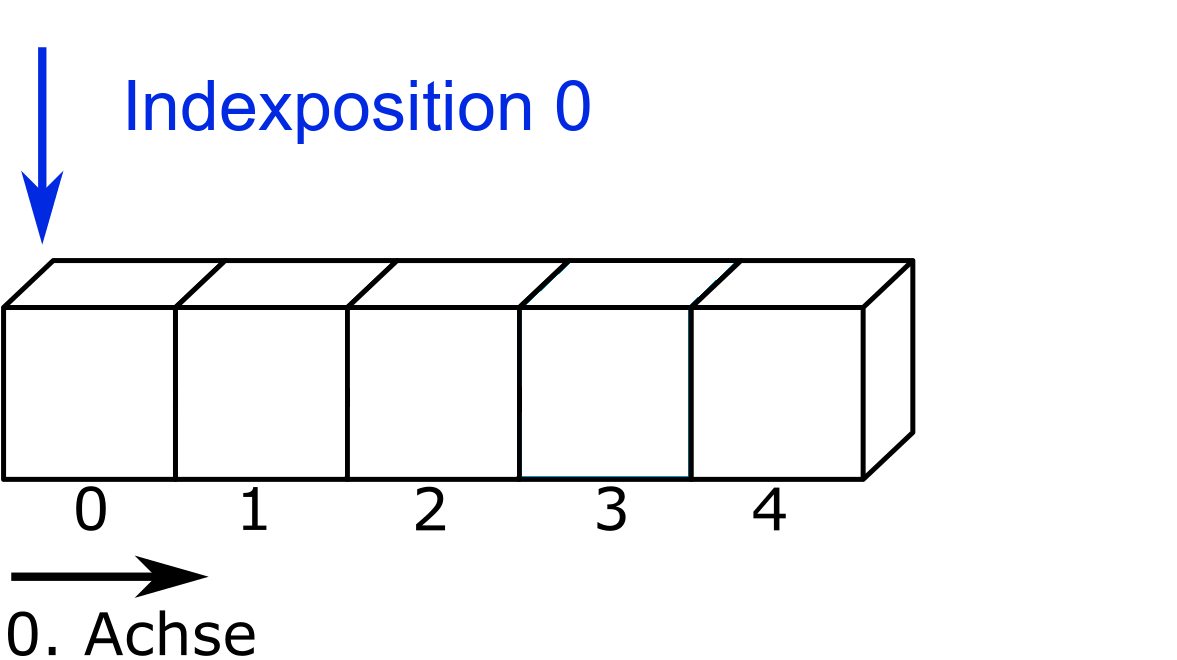
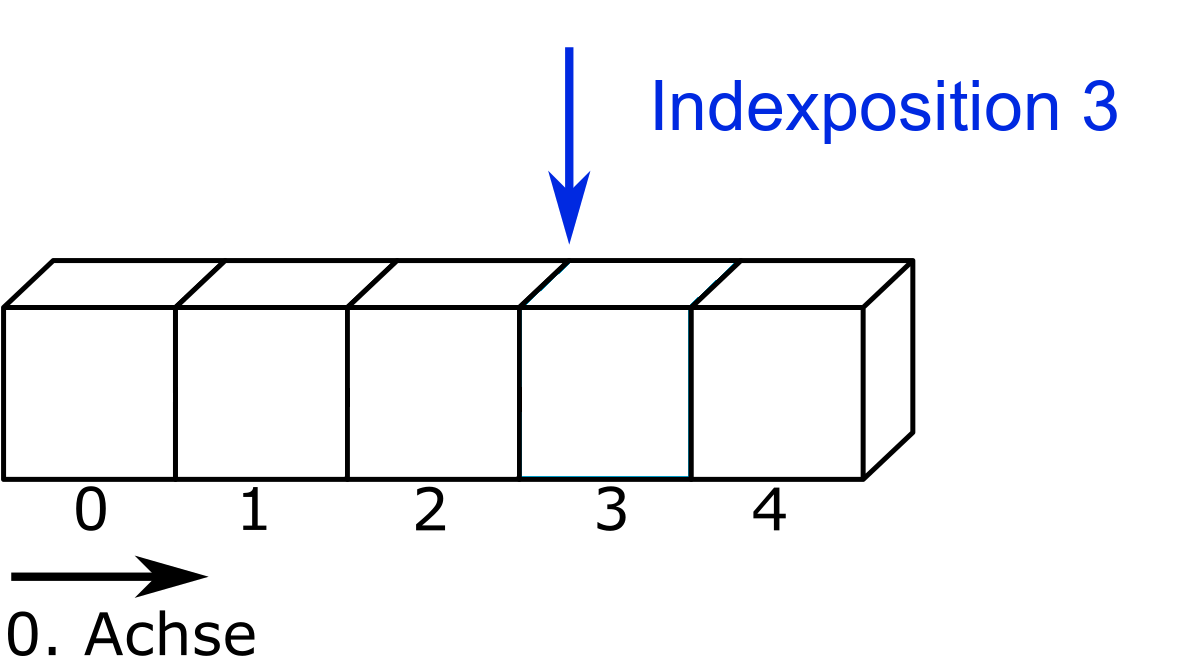
Hinweis 7.1: Dateizeiger in Python
Wird eine Datei zeilenweise oder mit der Methode .read() ausgelesen, wird der Dateizeiger um die angegebene Zeichenzahl bzw. bis ans Ende der Datei bewegt. Wird beispielsweise ein Datensatz ‘daten’ geöffnet und mit der Methode daten.read(3) die ersten drei Zeichen ausgelesen, bewegt sich der Dateizeiger von der Indexposition 0 zur Indexposition 3 (bzw. steht jeweils davor).
Die Methode daten.tell() gibt zurück, an welcher Position sich der Dateizeiger befindet.
Mit der Methode daten.seek(offset, whence = 0) wird der Zeiger an eine bestimmte Position gesetzt. Die Methode akzeptiert das Argument offset (Versatz) und das optionale Argument whence (woher), dessen Standardwert 0 (Dateianfang) ist. Für Zugriffe im Binärmodus (open(pfad, mode = 'rb')) kann das Argument whence außerdem die Werte 1 (aktuelle Position) oder 2 (Dateiende) annehmen.
daten.seek(0, 0)bezeichnet den Dateianfangdaten.seek(0, 1)bezeichnet die aktuelle Position in der Dateidaten.seek(0, 2)bezeichnet das Dateiendedaten.seek(-3, 2)bezeichnet das dritte Zeichen vor dem Dateiende
Wird der Dateizeiger mit der Methode datenobjekt.seek(0) an den Dateianfang gestellt, gelingt das Auslesen der Datei.
print(f"Position des Dateizeigers vor dem Zurücksetzen auf 0: {daten_maya.tell()}")
daten_maya.seek(0);
print(f"Position des Dateizeigers nach dem Zurücksetzen auf 0: {daten_maya.tell()}")
augen_maya = daten_maya.read()
print(f"Inhalt des Objekts augen_maya:\n{augen_maya}")Position des Dateizeigers vor dem Zurücksetzen auf 0: 28
Position des Dateizeigers nach dem Zurücksetzen auf 0: 0
Inhalt des Objekts augen_maya:
"5", "6", "2", "1", "4", "5"Geben Sie aus dem Datenobjekt daten_maya mit den Methoden .seek() und .read() die Zahlen and zweiter und dritter Stelle, also 6 und 2, aus.
Tipp 7.3: Musterlösung Dateizeiger bewegen
daten_maya.seek(6, 0);
print(daten_maya.read(1))
daten_maya.seek(daten_maya.tell() + 4, 0);
print(daten_maya.read(1))6
2Um Mayas Würfelergebnisse zu addieren, müssen die Zahlen extrahiert und in Ganzzahlen umgewandelt werden, da im Textmodus stets eine Zeichenfolge zurückgegeben wird.
print(type(augen_maya))<class 'str'>Dazu werden mit der Methode str.strip(") das führende und abschließende Anführungszeichen entfernt sowie anschließend mit der Methode str.split('", "') die Zeichenfolge über das Trennzeichen in eine Liste aufgeteilt. Anschließend werden die Listenelemente in Ganzzahlen umgewandelt und summiert. (Methoden der string-Bearbeitung werden im nächsten Abschnitt ausführlich behandelt.)
print(f"augen_maya:\n{augen_maya}")
augen_maya = augen_maya.strip('"')
print(f"\naugen_maya.strip('\"'):\n{augen_maya}")
augen_maya = augen_maya.split('", "')
print(f"\naugen_maya.split('\", \"'):\n{augen_maya}")
augen_maya_int = []
for i in augen_maya:
augen_maya_int.append(int(i))
print(f"\naugen_maya_int:\n{augen_maya_int}\n\nSumme Augen: {sum(augen_maya_int)}")augen_maya:
"5", "6", "2", "1", "4", "5"
augen_maya.strip('"'):
5", "6", "2", "1", "4", "5
augen_maya.split('", "'):
['5', '6', '2', '1', '4', '5']
augen_maya_int:
[5, 6, 2, 1, 4, 5]
Summe Augen: 23Datei schließen
Nach dem Zugriff auf die Datei, muss diese wieder geschlossen werden, um diese für andere Programme freizugeben.
daten_maya.close()
Hinweis 7.2: Schreiboperationen mit Python
Das Schließen einer Datei ist besonders für Schreiboperationen auf Datenobjekten wichtig. Andernfalls kann es passieren, dass Inhalte mit datenobjekt.write() nicht vollständig auf den Datenträger geschrieben werden. Siehe dazu die Dokumentation.
7.3 Aufgabe Dateien einlesen
Welche Augenzahl hat Hans erreicht?
Tipp 7.4: Musterlösung Augenzahlvergleich
# Erst Einlesen der Datei:
daten_hans = open(pfad_hans, mode = 'r', encoding = 'UTF-8')
augen_hans = daten_hans.read()
print(augen_hans)
# Hier muss man erkennen, dass Hans seinen Namen an den Anfang seiner Liste gesetzt hat. Dieser String muss also entfernt werden, bevor die Summe gebildet werden kann!
augen_hans = augen_hans.strip('"Hans", ')
augen_hans = augen_hans.strip('"')
augen_hans = augen_hans.split('", "')
print(augen_hans)
# print-Ausgabe zeigt, dass die Liste nun korrekt bereinigt wurde. Sie besteht nur noch aus Integerwerten und diese können summiert werden
# Neue (leere) Liste für die Würfe von Hans anlegen:
augen_hans_int = []
for i in augen_hans:
augen_hans_int.append(int(i))
print(f"Summe Augenzahl von Hans: {sum(augen_hans_int)}")"Hans", "3", "5", "1", "3", "2", "5"
['3', '5', '1', '3', '2', '5']
Summe Augenzahl von Hans: 19Musterlösung von Marc Sönnecken.
7.4 Daten interpretieren
Datensätze liegen typischerweise wenigstens in zweidimensionaler Form vor, d. h. die Daten sind in Zeilen und Spalten organisiert. Außerdem weisen Datensätze in der Regel auch unterschiedliche Datentypen auf. Die Funktion open(datei) gibt ein Dateiobjekt zurück, das mit Methoden wie zum Beispiel dateiobjekt.read() als Zeichenfolge eingelesen wird. Um die Daten sinnvoll weiterverarbeiten zu können, ist es deshalb notwendig, die Zeichenfolge korrekt zu interpretieren und Daten von Trennzeichen zu unterscheiden.
Für die Bearbeitung von Zeichenfolgen bietet Python eine Reihe von String-Methoden. Einige davon werden in diesem Kapitel exemplarisch verwendet. String-Methoden werden in der Regel mit einem führenden ‘str’ in der Form str.methode() genannt.
Beispielsweise soll eine Datei mit den Einwohnerzahlen der europäischen Länder eingelesen werden.
| Daten | Dateiname |
|---|---|
| Einwohner Europas | einwohner_europa_2019.csv |
Um einen Überblick über den Aufbau der Datei zu erhalten, werden die ersten drei Zeilen der Datei ausgegeben. Dafür kann die Datei zeilenweise mit einer for-Schleife durchlaufen werden, die mit dem Schlüsselwort break abgebrochen wird, wenn die Laufvariable den Wert 3 erreicht hat. Eine andere Möglichkeit ist die Methode dateiobjekt.readline(), die eine einzelne Zeile ausliest. Hier wird die Häufigkeit der Schleifenausführung über die Laufvariable mit for i in range(3): gesteuert.
dateipfad = "01-daten/einwohner_europa_2019.csv"
dateiobjekt_einwohner = open(dateipfad, 'r')
# erste 3 Zeilen anschauen
i = 0
for zeile in dateiobjekt_einwohner:
print(zeile)
i += 1
if i == 3:
break
# Datei schließen
dateiobjekt_einwohner.close()GEO,Value
Belgien,11467923
Bulgarien,7000039
Mit der Methode dateiobjekt.readline() kann eine einzelne Zeile eingelesen werden.
dateipfad = "01-daten/einwohner_europa_2019.csv"
dateiobjekt_einwohner = open(dateipfad, 'r')
for i in range(3):
print(dateiobjekt_einwohner.readline())
# Datei schließen
dateiobjekt_einwohner.close()GEO,Value
Belgien,11467923
Bulgarien,7000039
Die Datei hat also zwei Spalten. In der ersten Spalte sind die Ländernamen eingetragen, in der zweiten Spalte die Werte. Als Trennzeichen wird das Komma verwendet. In der ersten Zeile sind die Spaltenbeschriftungen eingetragen.
Im vorherigen Abschnitt haben wir die Methode dateiobjekt.read() kennengelernt, mit der eine Datei vollständig als string eingelesen wird. Zunächst wird die Datei mit der Methode dateiobjekt.read() in das Objekt einwohner eingelesen und wieder geschlossen.
dateipfad = "01-daten/einwohner_europa_2019.csv"
dateiobjekt_einwohner = open(dateipfad, 'r')
einwohner = dateiobjekt_einwohner.read()
print(einwohner)
# Datei schließen
dateiobjekt_einwohner.close();GEO,Value
Belgien,11467923
Bulgarien,7000039
Tschechien,10528984
Daenemark,5799763
Deutschland einschliesslich ehemalige DDR,82940663
Estland,1324820
Irland,4904240
Griechenland,10722287
Spanien,46934632
Frankreich,67028048
Kroatien,4076246
Italien,61068437
Zypern,875898
Lettland,1919968
Litauen,2794184
Luxemburg,612179
Uganda,-1
Ungarn,9772756
Malta,493559
Niederlande,17423013
Oesterreich,8842000
Polen,37972812
Portugal,10276617
Rumaenien,19405156
Slowenien,2080908
Slowakei,5450421
Finnland,5512119
Schweden,10243000
Vereinigtes Koenigreich,66647112
Anschließend können die eingelesenen Daten mit der Methode str.split('\n') zeilweise aufgeteilt werden. Mit '\n' wird als Argument der Zeilenumbruch übergeben. Die Methode liefert eine Liste zurück.
liste_einwohner_zeilenweise = einwohner.split("\n")
print(liste_einwohner_zeilenweise[0:3])['GEO,Value', 'Belgien,11467923', 'Bulgarien,7000039']Die Liste enthält an der Indexposition die Spaltenbeschriftungen. Diese können mit der Methode liste.pop(index) aus der Liste entfernt und zugleich in einem neuen Objekt gespeichert werden.
spaltennamen = liste_einwohner_zeilenweise.pop(0)
spaltennamen = spaltennamen.split(',')
print(f"Überschrift Spalte 0: {spaltennamen[0]}\tÜberschrift Spalte 1: {spaltennamen[1]}")Überschrift Spalte 0: GEO Überschrift Spalte 1: ValueAnschließend kann die Liste mit der Methode str.split(',') nach Ländern und Werten aufgeteilt werden. Der Vorgang bricht allerdings mit einer Fehlermeldung ab. Die Fehlermeldung wird im folgenden Code-Block per Ausnahmebehandlung abgefangen. Neben der Fehlermeldung werden der verursachende Listeneintrag und dessen Indexposition ausgegeben.
# Leere Listen vor der Schleife anlegen
geo = []
einwohnerzahl = []
try:
for zeile in liste_einwohner_zeilenweise:
eintrag = zeile.split(',')
geo.append(eintrag[0])
einwohnerzahl.append(eintrag[1])
print(spaltennamen[0])
print(geo, "\n")
print(spaltennamen[1])
print(einwohnerzahl)
except Exception as error:
# print Fehlermeldung
print(f"Fehlermeldung: {error}")
# print Eintrag und Index
print(f"Eintrag: {eintrag}\t Zeilenindex: {liste_einwohner_zeilenweise.index(zeile)}")Fehlermeldung: list index out of range
Eintrag: [''] Zeilenindex: 29Die Fehlermeldung ist so zu deuten, dass eine der Listenoperationen mit dem Slice Operator einen ungültigen Index anspricht. Leicht angepasst, liefert der Code-Block auch die Ursache der Fehlermeldung.
Wird die leere Zeile aus der Liste entfernt, klappt das Aufteilen der Ländernamen und der Werte.
# leere Zeile entfernen
liste_einwohner_zeilenweise.remove('')
# Leere Listen vor der Schleife anlegen
geo = []
einwohnerzahl = []
try:
for zeile in liste_einwohner_zeilenweise:
eintrag = zeile.split(',')
geo.append(eintrag[0])
einwohnerzahl.append(eintrag[1])
print(spaltennamen[0])
print(geo, "\n")
print(spaltennamen[1])
print(einwohnerzahl)
except IndexError as error:
print(error)GEO
['Belgien', 'Bulgarien', 'Tschechien', 'Daenemark', 'Deutschland einschliesslich ehemalige DDR', 'Estland', 'Irland', 'Griechenland', 'Spanien', 'Frankreich', 'Kroatien', 'Italien', 'Zypern', 'Lettland', 'Litauen', 'Luxemburg', 'Uganda', 'Ungarn', 'Malta', 'Niederlande', 'Oesterreich', 'Polen', 'Portugal', 'Rumaenien', 'Slowenien', 'Slowakei', 'Finnland', 'Schweden', 'Vereinigtes Koenigreich']
Value
['11467923', '7000039', '10528984', '5799763', '82940663', '1324820', '4904240', '10722287', '46934632', '67028048', '4076246', '61068437', '875898', '1919968', '2794184', '612179', '-1', '9772756', '493559', '17423013', '8842000', '37972812', '10276617', '19405156', '2080908', '5450421', '5512119', '10243000', '66647112']7.5 Aufgabe Daten interpretieren
Bestimmen Sie das Minimum und das Maximum der Einwohnerzahl und die dazugehörigen Länder.
Bereinigen Sie ggf. fehlerhafte Werte.
Wie viele Einwohner leben in Europa insgesamt?
Welchen Datentyp hat die Liste einwohnerzahl?
Welchen Datentyp haben die Einträge der Liste einwohnerzahl?
TippMusterlösung vollständiges Einlesen
# 1. Minimum und Maximum der Einwohnerzahlen und dazugehörige Länder bestimmen
liste_einwohner = []
for ele in einwohnerzahl:
liste_einwohner.append(int(ele))
# Umwandeln der Strings in Integer bei der Einwohnerzahl
einwohnerzahl = [int(zahl) for zahl in einwohnerzahl]
# 2. Fehler bereinigen
# Sowohl der Fehler in der Liste der Einwohnerzahlen als auch das entsprechende Land werden entfernt.
for i in range(len(einwohnerzahl) -1,-1,-1): # Hiermit wird rückwärts durch die Liste iteriert, damit das Entfernen eines Elements die Indizes der bereits durchlaufenen Elemente nicht beeinflusst
if einwohnerzahl[i] < 0:
einwohnerzahl.pop(i)
geo.pop(i)
for i in range(len(einwohnerzahl)):
if einwohnerzahl[i] == max(einwohnerzahl):
maximum = i
elif einwohnerzahl[i] == min(einwohnerzahl):
minimum = i
maximum_land = geo[maximum]
minimum_land = geo[minimum]
print(f"Maximum: {maximum_land} mit {max(einwohnerzahl)} Einwohnern")
print(f"Minimum: {minimum_land} mit {min(einwohnerzahl)} Einwohnern")
# 3. Einwohner Europa insgesamt
pop_gesamt = sum(einwohnerzahl) # Uganda gehört nicht zu Europa, wurde durch die Fehlerbehandlung aber bereits entfernt
print(f"Die Summe aller Einwohner in Europa beträgt {pop_gesamt}")
# 4.
print(f"Die Liste einwohnerzahl hat den Datentypen {type(einwohnerzahl)}")
print(f"Die Einträge der Liste haben den Datentypen {type(einwohnerzahl[0])}")Maximum: Deutschland einschliesslich ehemalige DDR mit 82940663 Einwohnern
Minimum: Malta mit 493559 Einwohnern
Die Summe aller Einwohner in Europa beträgt 514117784
Die Liste einwohnerzahl hat den Datentypen <class 'list'>
Die Einträge der Liste haben den Datentypen <class 'int'>Musterlösung von Marc Sönnecken.
7.6 Einlesen als Liste
Ein Dateiobjekt kann auch direkt als Liste eingelesen werden. Die Methode dateiobjekt.readlines() gibt eine Liste zurück, in der jede Zeile einen Eintrag darstellt. Ebenso kann die Listenfunktion list() auf Dateiobjekte angewendet werden. Beide Vorgehensweisen liefern die gleiche Liste zurück, in der der Zeilenumbruch \n mit ausgelesen wird.
dateipfad = "01-daten/einwohner_europa_2019.csv"
dateiobjekt_einwohner = open(dateipfad, 'r')
# Methode readlines
einwohner = dateiobjekt_einwohner.readlines()
print(einwohner)
## Dateizeiger zurücksetzen
dateiobjekt_einwohner.seek(0);
# Funktion list
einwohner = list(dateiobjekt_einwohner)
print(einwohner)
# Datei schließen
dateiobjekt_einwohner.close();['GEO,Value\n', 'Belgien,11467923\n', 'Bulgarien,7000039\n', 'Tschechien,10528984\n', 'Daenemark,5799763\n', 'Deutschland einschliesslich ehemalige DDR,82940663\n', 'Estland,1324820\n', 'Irland,4904240\n', 'Griechenland,10722287\n', 'Spanien,46934632\n', 'Frankreich,67028048\n', 'Kroatien,4076246\n', 'Italien,61068437\n', 'Zypern,875898\n', 'Lettland,1919968\n', 'Litauen,2794184\n', 'Luxemburg,612179\n', 'Uganda,-1\n', 'Ungarn,9772756\n', 'Malta,493559\n', 'Niederlande,17423013\n', 'Oesterreich,8842000\n', 'Polen,37972812\n', 'Portugal,10276617\n', 'Rumaenien,19405156\n', 'Slowenien,2080908\n', 'Slowakei,5450421\n', 'Finnland,5512119\n', 'Schweden,10243000\n', 'Vereinigtes Koenigreich,66647112\n']
['GEO,Value\n', 'Belgien,11467923\n', 'Bulgarien,7000039\n', 'Tschechien,10528984\n', 'Daenemark,5799763\n', 'Deutschland einschliesslich ehemalige DDR,82940663\n', 'Estland,1324820\n', 'Irland,4904240\n', 'Griechenland,10722287\n', 'Spanien,46934632\n', 'Frankreich,67028048\n', 'Kroatien,4076246\n', 'Italien,61068437\n', 'Zypern,875898\n', 'Lettland,1919968\n', 'Litauen,2794184\n', 'Luxemburg,612179\n', 'Uganda,-1\n', 'Ungarn,9772756\n', 'Malta,493559\n', 'Niederlande,17423013\n', 'Oesterreich,8842000\n', 'Polen,37972812\n', 'Portugal,10276617\n', 'Rumaenien,19405156\n', 'Slowenien,2080908\n', 'Slowakei,5450421\n', 'Finnland,5512119\n', 'Schweden,10243000\n', 'Vereinigtes Koenigreich,66647112\n']Um den Zeilenumbruch zu entfernen, könnte mit dem Slice Operator das letzte Zeichen jedes Listeneintrags entfernt werden.
Eine andere Möglichkeit ist die Methode str.replace(old, new, count=-1), mit der Zeichen ersetzt oder gelöscht werden können. Die Parameter old und new geben die zu ersetzende bzw. die einzusetzende Zeichenfolge an und müssen positional übergeben werden. Über den Parameter count kann eingestellt werden, wie oft die Zeichenfolge old ersetzt werden soll. Standardmäßig wird jedes Vorkommen ersetzt.
print('Hund'.replace('Hu', 'Mu'))
zeichenfolge = 'Ein kurzer Text ohne doppelte Leerzeichen.'
print(zeichenfolge.replace(' ', ' '))Mund
Ein kurzer Text ohne doppelte Leerzeichen.Die Methode str.replace() kann auch zum Löschen verwendet werden. Wird für den Parameter new eine leere Zeichenfolge übergeben, wird die in old übergebene Zeichenfolge gelöscht.
print(zeichenfolge.replace(' ', '').replace('doppelte', ''))EinkurzerTextohneLeerzeichen.Mit der Methode str.replace() kann die eingelesene Liste um den Zeilenumbruch bereinigt werden.
dateipfad = "01-daten/einwohner_europa_2019.csv"
dateiobjekt_einwohner = open(dateipfad, 'r')
# Methode readlines
einwohner = dateiobjekt_einwohner.readlines()
einwohner_neu = []
for element in einwohner:
einwohner_neu.append(element.replace('\n', ''))
einwohner = einwohner_neu
print(einwohner)
# Datei schließen
dateiobjekt_einwohner.close();['GEO,Value', 'Belgien,11467923', 'Bulgarien,7000039', 'Tschechien,10528984', 'Daenemark,5799763', 'Deutschland einschliesslich ehemalige DDR,82940663', 'Estland,1324820', 'Irland,4904240', 'Griechenland,10722287', 'Spanien,46934632', 'Frankreich,67028048', 'Kroatien,4076246', 'Italien,61068437', 'Zypern,875898', 'Lettland,1919968', 'Litauen,2794184', 'Luxemburg,612179', 'Uganda,-1', 'Ungarn,9772756', 'Malta,493559', 'Niederlande,17423013', 'Oesterreich,8842000', 'Polen,37972812', 'Portugal,10276617', 'Rumaenien,19405156', 'Slowenien,2080908', 'Slowakei,5450421', 'Finnland,5512119', 'Schweden,10243000', 'Vereinigtes Koenigreich,66647112']7.7 Dateien schreiben
Um Dateien zu schreiben, müssen diese mit der write-Methode eines Dateiobjekts verwendet werden. Dieser Methode wird als Argument die zu schreibende Zeichenfolge übergeben.
dateipfad = "01-daten/neue_datei.txt"
# Öffne Datei zum Schreiben öffnen
datei = open(dateipfad, mode = 'w')
# Inhalt in die Datei schreiben
datei.write("Prokrastination an Hochschulen\n\n".upper())
datei.write("KAPITEL 1: Aller Anfang ist schwer\nPlatzhalter: Den Rest schreibe ich später.")
# Datei schließen
datei.close()Die Datei kann nun ausgelesen werden.
dateiinhalt = open(dateipfad, mode = 'r')
text = dateiinhalt.read()
print(text)
dateiinhalt.close()PROKRASTINATION AN HOCHSCHULEN
KAPITEL 1: Aller Anfang ist schwer
Platzhalter: Den Rest schreibe ich später.7.8 Aufgabe Dateien schreiben
- Erzeugen Sie eine neue Datei mit der Endung
.txt, die den Namen ihrer Heimatstadt hat. Schreiben Sie in diese Datei 10 Zeilen mit Informationen zur Stadt.
(Arnold (2023))
Arnold, Simone. 2023. „Datenanalyse mit Python. Funktionen Module Dateien.“ Fachhochschule Dortmund.