Häufig liegen Sensordaten in mehreren Dateien vor. Mögliche Gründe dafür können sein, dass die Messung
von unterschiedlichen Personen,
an unterschiedlichen Standorten,
zu unterschiedlichen Zeiten,
mit verschiedenen Geräten oder
für unterschiedliche Messgrößen durchgeführt wurden.
Im Ordner ‘01-daten/hooke’ liegen mehrere txt-Dateien mit Messdaten zur Federausdehnung. In diesem Kapitel sollen Sie das bisher Gelernte anwenden und die folgenden Fragen beantworten.
Liegen ungültige Messungen vor?
Welche Werte können für die Federkonstanten ermittelt werden?
Wurden die Messungen mit der gleichen Feder (oder mit Federn mit gleicher Federkonstante) durchgeführt, wenn als Vertrauenswahrscheinlichkeit 90 % bzw. 95 % angenommen werden soll?
Im Abschnitt Kapitel 5.1 finden Sie Hinweise und im Abschnitt Kapitel 5.2 eine Musterlösung zum Einlesen der Dateien. Anschließend sollen Sie die Aufgabenstellung eigenständig bearbeiten. In Abschnitt Kapitel 5.3 finden Sie eine Musterlösung für die Aufbereitung der Daten. In Kapitel 5.4 die Musterlösung zur Bestimmung der Federkonstanten.
Hinweis: Je nach gewähltem Vorgehen können sich unterschiedliche Ergebnisse ergeben (etwa bei der Bewertung von und dem Umgang mit Extremwerten / Ausreißern).
Zunächst kann der Funktion glob.glob() das Argument pathname = * übergeben werden. Der Platzhalter * steht für eine beliebige Zeichenfolge (außer Dateipfadelemente wie / oder .), sodass die Namen aller im angegebenen Ordner gespeicherten Dateien ausgelesen werden. Auf diese Weise kann die Anzahl der Dateien und die Dateiendung bestimmt werden, falls dies noch unbekannt ist.
Mit den Dateipfaden können die Dateien mit Hilfe einer Schleife in eine Liste eingelesen werden. Zunächst werden nur die jeweils ersten 3 Zeilen eingelesen, um einen Eindruck vom Aufbau der Dateien zu erhalten.
for pfad in pfadliste: zwischenspeicher = pd.read_csv(filepath_or_buffer = ordnerpfad +'/'+ pfad, nrows =3)print(pfad, "\n", zwischenspeicher, "\n", sep ='')
Die Dateien beinhalten keine Spaltenbeschriftung und verwenden den Tabulator ‘\t’ als Trennzeichen. Die erste Spalte enthält einen Zeitstempel, die zweite die gemessene Federausdehnung und die dritte (vermutlich) das angehängte Gewicht.
Die Dateien mit dem Modul glob automatisch einlesen und in einer Datei zusammenführen.
Die verschiedenen Möglichkeiten sind mit zunehmend mehr Aufwand beim Programmieren verbunden. Je mehr separate Dateien Sie auswerten möchten, desto mehr Automatisierung ist gefragt. Da bei der Auswertung von Sensordaten häufig zahlreiche Dateien ausgewertet werden müssen, wird in der Musterlösung Variante c) gezeigt.
Tipp 5.1: Schrittweises Vorgehen
Das Einlesen der Dateien wird voraussichtlich der aufwändigste und fehleranfälligste Arbeitsschritt sein. Entwickeln Sie Ihre Lösung Schritt für Schritt. Beginnen Sie mit der Variante a). Wenn Sie die Dateien eingelesen haben, können Sie sich durch die Weiterentwicklung zur Variante b) mit dem Modul glob vertraut machen. Darauf aufbauend können Sie mit der Variante c) die Automatisierung für beliebig viele Dateien umsetzen.
Tipp 5.2: Musterlösung Dateien einlesen
Der erste Versuch, die Dateien einzulesen, scheitert mit einer Fehlermeldung. Die Anweisungen werden deshalb in die Struktur zur Ausnahmebehandlung eingebettet und die verursachende Datei abgefangen. (Sollten mehrere Dateien Fehler erzeugen, müssten die Dateien in einer Liste gespeichert und später - falls möglich - mit einer Schleife weiter behandelt werden.)
team_ma.txt
Error tokenizing data. C error: Expected 3 fields in line 135, saw 4
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 359 entries, 0 to 358
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Zeit 355 non-null object
1 Abstand 355 non-null object
2 Gewicht 355 non-null object
3 Team 359 non-null object
dtypes: object(4)
memory usage: 11.3+ KB
None
Erfolgreich einglesen:
['fabi' 'kreativkoepfe' 'die_ahnungslosen']
Der Fehlermeldung zufolge besteht Zeile 135 aus 4 statt aus 3 Spalten. Die fehlerverursachende Datei wird deshalb zeilenweise durchlaufen und jede Zeile ausgegeben, die mehr als 3 Einträge hat. Zur Kontrolle werden auch die ersten 5 Zeilen ausgegeben.
# einen leeren DataFrame mit 3 Spalten erstellendf = pd.DataFrame(data = [], columns = ['Zeit', 'Abstand', 'Gewicht'])dateiobjekt_problem_datei =open(file= ordnerpfad +'/'+ pfad_problem_datei, mode ='r')index =0for zeile in dateiobjekt_problem_datei:try: zwischenspeicher = zeile.split(sep ="\t")iflen(zwischenspeicher) >3:print("Index =", index, ":", zwischenspeicher)elif index <=5:print(zeile) index +=1exceptExceptionas error:print(error)dateiobjekt_problem_datei.close()
10:09:38 109.26 cm 0
10:09:41 109.26 cm 0
10:09:44 109.28 cm 0
Index = 134 : ['10:29:27', '105.49 cm', '300', '\n']
Jede zweite Zeile ist leer. In Zeile 134 wird ein Zeilenumbruch ‘\n’ eingelesen. Die Datei wird deshalb mit einer angepassten Schleife erneut durchlaufen. Aus der betreffenden Zeile wird der zusätzliche Zeilenumbruch ‘\n’ entfernt. Leere Zeilen werden übersprungen. Die korrekten Zeilen werden an den DataFrame hooke angefügt.
Der Code muss ggf. noch angepasst werden, weil vermutlich so leere zeilen angefügt werden
Ob alle Elemente einer Zelle numerisch sind, kann mit der Pandas-Methode pd.Series.str.isnumeric() überprüft werden. Ein Blick auf die Daten zeigt die Ursache.
Anzahl der studentisierten z-Werte mit Betrag ≥ 3: 0
Anzahl der studentisierten z-Werte mit Betrag ≥ 2.5: 1
Zeit Abstand Gewicht Team
359 10:09:38 109.26 0.0 die_ahnungslosen
Kombinationen aus Gewicht & Team bestimmen
die_ahnungslosen
359 0.0
Name: Gewicht, dtype: float64
# z-Werte größer gleich abs(3) findenz_values_ge3_sum = hooke.groupby(by = ['Team', 'Gewicht'])['Abstand'].apply(lambda x: scipy.stats.zscore(x, ddof =1)).abs().ge(3).sum()print("Anzahl der studentisierten z-Werte mit Betrag ≥ 3:", z_values_ge3_sum)# z-Werte größer gleich abs(2.5) findenz_values_ge25_sum = hooke.groupby(by = ['Team', 'Gewicht'])['Abstand'].apply(lambda x: scipy.stats.zscore(x, ddof =1)).abs().ge(2.5).sum()print("Anzahl der studentisierten z-Werte mit Betrag ≥ 2.5:", z_values_ge25_sum)# Die Zeilen mit z-Werten größer abs(2.5) ausgebenbool_index = hooke.groupby(by = ['Team', 'Gewicht'])['Abstand'].apply(lambda x: scipy.stats.zscore(x, ddof =1)).abs().ge(2.5).valuesz_values_ge_25 = hooke.iloc[bool_index , :]print(z_values_ge_25, "\n")# Kombinationen aus Gewicht & Team bestimmenteams = z_values_ge_25['Team'].unique()## teams durchlaufen und jeweils die Gewichte speichernteam_gewichte = [] # leere listefor i inrange(len(teams)):print(teams[i])print(z_values_ge_25.loc[z_values_ge_25['Team'] == teams[i], 'Gewicht'], "\n") team_gewichte.append(z_values_ge_25.loc[z_values_ge_25['Team'] == teams[i], 'Gewicht'].values)print(team_gewichte, "\n")# Messreihen auswählenmessreihen = pd.DataFrame()for i inrange(len(teams)):for j inrange(len(team_gewichte[i])):print(teams[i], team_gewichte[i][j]) messreihen = pd.concat([messreihen, hooke.loc[ (hooke['Team'] == teams[i]) & (hooke['Gewicht'] == team_gewichte[i][j]) ]])# studentisierte z-Werte der Messreihen bildenmessreihen_z_scores = messreihen.groupby(by = ['Team', 'Gewicht'])['Abstand'].apply(lambda x: scipy.stats.zscore(x, ddof =1)).reset_index(drop =True)# gemeinsame Ausgabe der Datenmessreihen.insert(loc =2, column ='z-Werte Abstand', value = messreihen_z_scores.values)print(messreihen)
Die Werte können mit der Pandas-Methode pd.plot() mit wenig Aufwand dargestellt werden. Die Methode ist jedoch nicht so flexibel, wie das Paket matplotlib. So ist das Punktdiagramm (kind = 'scatter') nur für DataFrames, nicht aber für groupby-Objekte verfügbar. Dies wird durch das Setzen eines Markers und die Einstellung der Liniendicke auf 0 kompensiert.
Die Werte, die betragsmäßig studentisierte z-Werte \(\ge\) 2,5 aufweisen, könnten als Ausreißer entfernt werden. In diesem Fall wird darauf verzichtet.
Umwandlung der Rechengrößen
Im nächsten Schritt wird die Abstandsmessung auf den Nullpunkt normiert, um die Federausdehnung abzubilden. Ebenso wird das Gewicht in \(g\) in die wirkende Kraft in \(N\) umgerechnet.
Tipp 5.3: Musterlösung
Abstandsmessung auf Meter und auf den Nullpunkt normieren
Abstandsmessung auf den Nullpunkt normieren. Die Spalte Abstand wird in Abständsänderung umbenannt.
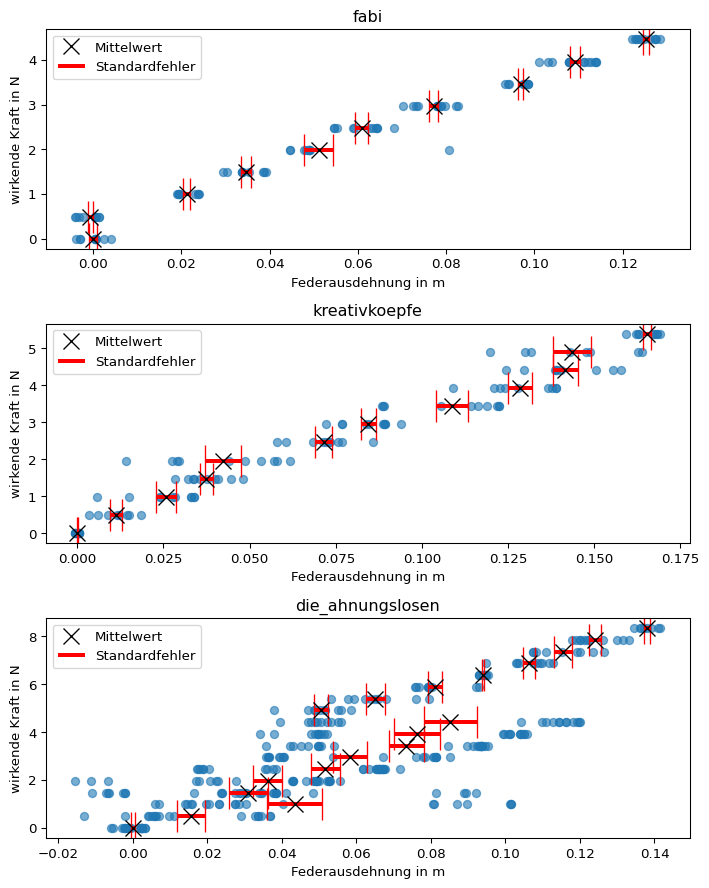
Da es nur vier Teams gibt, können die Messreihen grafisch dargestellt werden. Eine mögliche Darstellung können Sie dem ersten Reiter, die Zwischenschritte und Schlussfolgerungen den folgenden Reitern entnehmen.
Die Ausgabe ist aus Platzgründen auf die ersten Zeilen beschränkt.
Mittelwerte der Abstandsänderung nach Team und Kraft:
Team Kraft
die_ahnungslosen 0.0000 -3.558352e-17
0.4905 1.559056e-02
0.9810 4.339409e-02
1.4715 3.099500e-02
1.9620 3.612204e-02
Name: Federausdehnung, dtype: float64
Standardfehler der Mittelwerte nach Team und Kraft
Team Kraft
die_ahnungslosen 0.0000 0.000642
0.4905 0.003751
0.9810 0.007456
1.4715 0.005197
1.9620 0.004018
Name: Standardfehler, dtype: float64
# Mittelwerte der Teams nach Kraftdistance_means_by_team_and_force = hooke.groupby(by = [hooke['Team'], hooke['Kraft']])['Abstandsänderung'].mean()distance_means_by_team_and_force.name ='Federausdehnung'print("Mittelwerte der Abstandsänderung nach Team und Kraft:", distance_means_by_team_and_force.head(), sep ='\n')print() # leere Zeile# Standardfehler der Teams nach Kraftdistance_stderrors_by_team_and_force = hooke.groupby(by = [hooke['Team'], hooke['Kraft']])['Abstandsänderung'].std(ddof =1).div(np.sqrt(hooke['Abstandsänderung'].groupby(by = [hooke['Team'], hooke['Kraft']]).size()))distance_stderrors_by_team_and_force.name ='Standardfehler'print("Standardfehler der Mittelwerte nach Team und Kraft", distance_stderrors_by_team_and_force.head(), sep ='\n')# grafische Darstellunganzahl_teams = hooke['Team'].unique().sizeplt.figure(figsize = (7.5, 12))for i inrange(anzahl_teams): plt.subplot(4, 1, i +1) # plt.subplot zählt ab 1# Punktdiagramm plotting_data = hooke.loc[hooke['Team'] == hooke['Team'].unique()[i], :] plt.scatter(x = plotting_data['Abstandsänderung'], y = plotting_data['Kraft'], alpha =0.6) plt.title(label = hooke['Team'].unique()[i]) plt.xlabel("Federausdehnung in m") plt.ylabel("wirkende Kraft in N")# # Fehlerbalken distance_means_by_force = plotting_data.groupby(by = plotting_data['Kraft'])['Abstandsänderung'].mean() distance_stderrors_by_force = plotting_data.groupby(by = plotting_data['Kraft'])['Abstandsänderung'].std(ddof =1).div(np.sqrt(plotting_data['Abstandsänderung'].groupby(by = plotting_data['Kraft']).size())) errorbar_container = plt.errorbar(x = distance_means_by_force, y = distance_means_by_force.index, xerr = distance_stderrors_by_force, linestyle ='none', marker ='x', color ='black', markersize =12, elinewidth =3, ecolor ='red', capsize =12)# siehe: https://matplotlib.org/stable/api/container_api.html#matplotlib.container.ErrorbarContainer plt.legend([errorbar_container.lines[0], errorbar_container.lines[2][0]], ['Mittelwert', 'Standardfehler'], loc ='upper left')plt.tight_layout()plt.show()
Die Messreihen des Teams die_ahnungslosen entsprechen dem erwarteten linearen Trend.
Bei Team fabi scheint für das erste angehängte Gewicht (50 Gramm) ein Fehler bei der Datenerhebung vorzuliegen. Vermutlich wurde hier mit 0 Gramm gemessen.
Die Messreihen des Teams kreativköpfe entsprechen weitgehend dem erwarteten linearen Trend.
Die Messreihen des Teams ma scheinen wenigstens für die ersten vier angehängten Gewichten durch grobe Messfehler geprägt zu sein.
Die Messreihe des Teams ma wird wegen grober Messfehler aus dem Datensatz entfernt. Aus der Messreihe des Teams fabi wird die Messung für das Gewicht 50 Gramm entfernt.
Bei einer großen Anzahl an Datensätzen kann auch die grafische Kontrolle an Grenzen stoßen. In diesem Fall empfiehlt es sich, die visuellen und kennzahlenbasierten Methoden zusammen zu nutzen, um Muster zu identifizieren und für eine große Zahl von Messungen zu überprüfen. Beispielsweise könnten nach einer visuellen Inspektion von Messreihen mit Extremwerten bzw. Ausreißern alle Messreihen daraufhin überprüft werden, ob mit zunehmenden Gewicht stets auch die mittlere Federausdehnung größer als für leichtere Gewichte ist. Abweichende Messreihen könnten dann grafisch kontrolliert werden.
5.4 Musterlösung Federkonstanten bestimmen
Im nächsten Schritt können die Federkonstanten mittels linearer Regression bestimmt werden.
Welche Werte können für die Federkonstanten ermittelt werden?
Wurden die Messungen mit der gleichen Feder durchgeführt, wenn als Vertrauenswahrscheinlichkeit 90 % bzw. 95 % angenommen werden soll?
Die Punktschätzung der Federkonstante von Team fabi 34.105 liegt im 95-%-Konfidenzintervall der Messung von Team die_ahnungslosen 33.998 ≤ 34.918 ≤ 35.838. Die Punktschätzung der Federkonstante von Team fabi 34.105 liegt aber nicht im 90-%-Konfidenzintervall der Messung von Team die_ahnungslosen 34.148 ≤ 34.918 ≤ 35.689.
Unabhängig vom gewählten Vertrauensniveau liegt die Punktschätzung der Federkonstante von Team kreativkoepfe 29.764 nicht in den Konfidenzintervallen der beiden übrigen Teams.
Hinweis 5.1: Ergebnisse
Abhängig vom gewählten Vorgehen sind andere Ergebnisse möglich, beispielsweise durch das Entfernen von als Ausreißern eingestuften Einzelwerten oder einer anderen Behandlung der Messreihe vom Team fabi für das angehängte Gewicht 50 Gramm.