data("metaIndex")
d_stationen <- metaIndex |>
filter(var == "wind", res == "10_minutes") |>
mutate(Dauer = round(as.numeric(bis_datum - von_datum) / 365.25)) |>
arrange(desc(Dauer)) |>
select(von_datum, bis_datum, Dauer, Stationsname, Bundesland) |>
as_tibble()
d_stationenArbeiten mit Zeitreihen
2026-03-19
Begriff der Zeitreihe
Eine “Zeitreihe” ist eine zeitlich geordnete Folge von Beobachtungen, bei der sich die Anordnung der Merkmalsausprägungen zwingend aus dem Zeitablauf ergibt (etwa Aktienkurse, Bevölkerungsentwicklung, Wetterdaten).
Die einzelnen Zeitpunkte werden zu einer Menge von Beobachtungszeitpunkten \(T\) zusammengefasst, bei der für jeden Zeitpunkt \(t \in T\) genau eine Beobachtung vorliegt. Zeitreihen treten in fast allen Bereichen der Wissenschaft auf.
Plot der Rohdaten
ggplot(data = d_wind_raw_ts) +
geom_line(mapping = aes(x = Datum, y = Geschwindigkeit))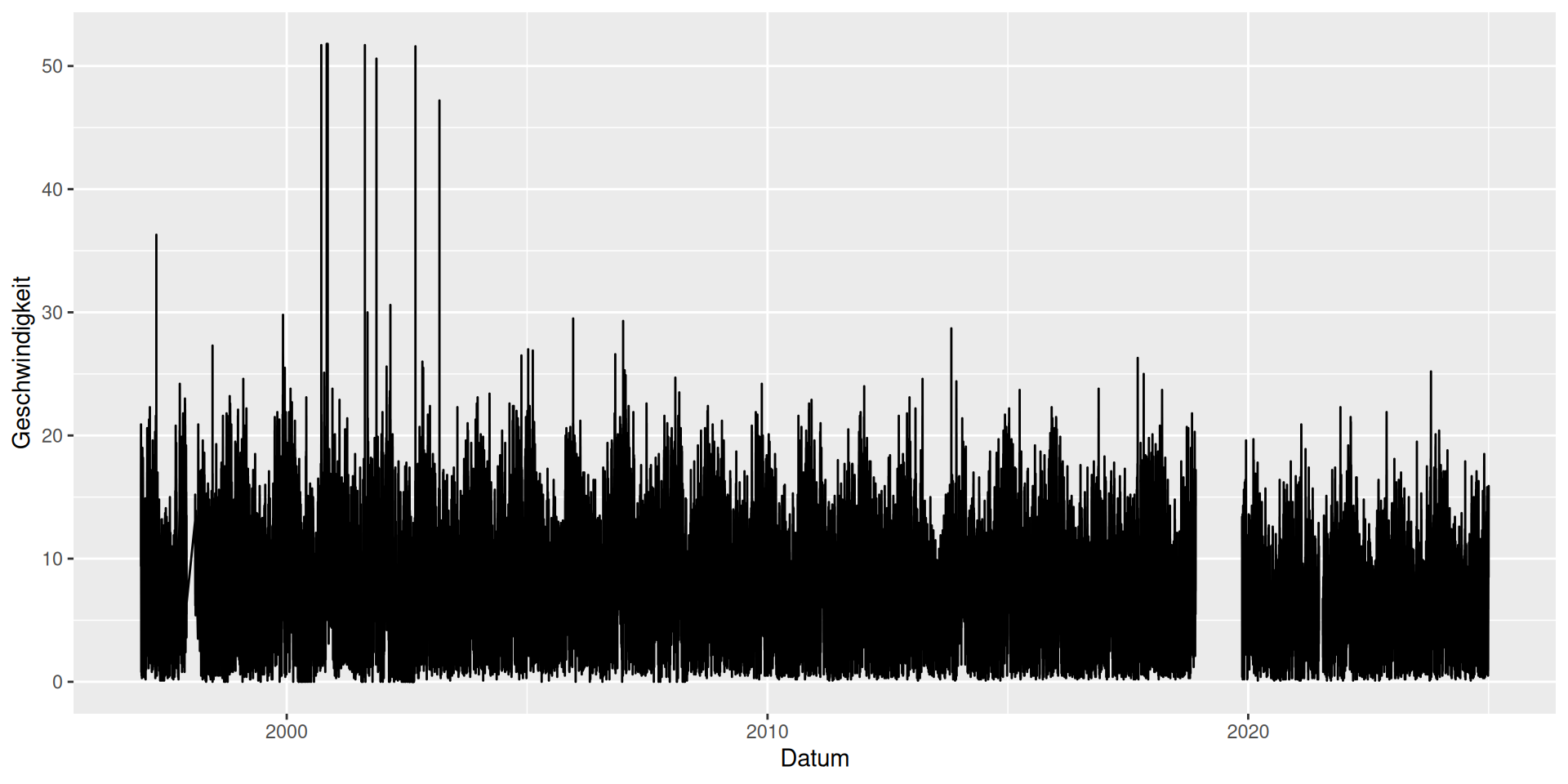
Lücken im Datensatz, erste Lücke mit Linie verbunden!
Plot
ggplot(d_wind) +
geom_line(mapping = aes(x = Datum, y = Geschwindigkeit))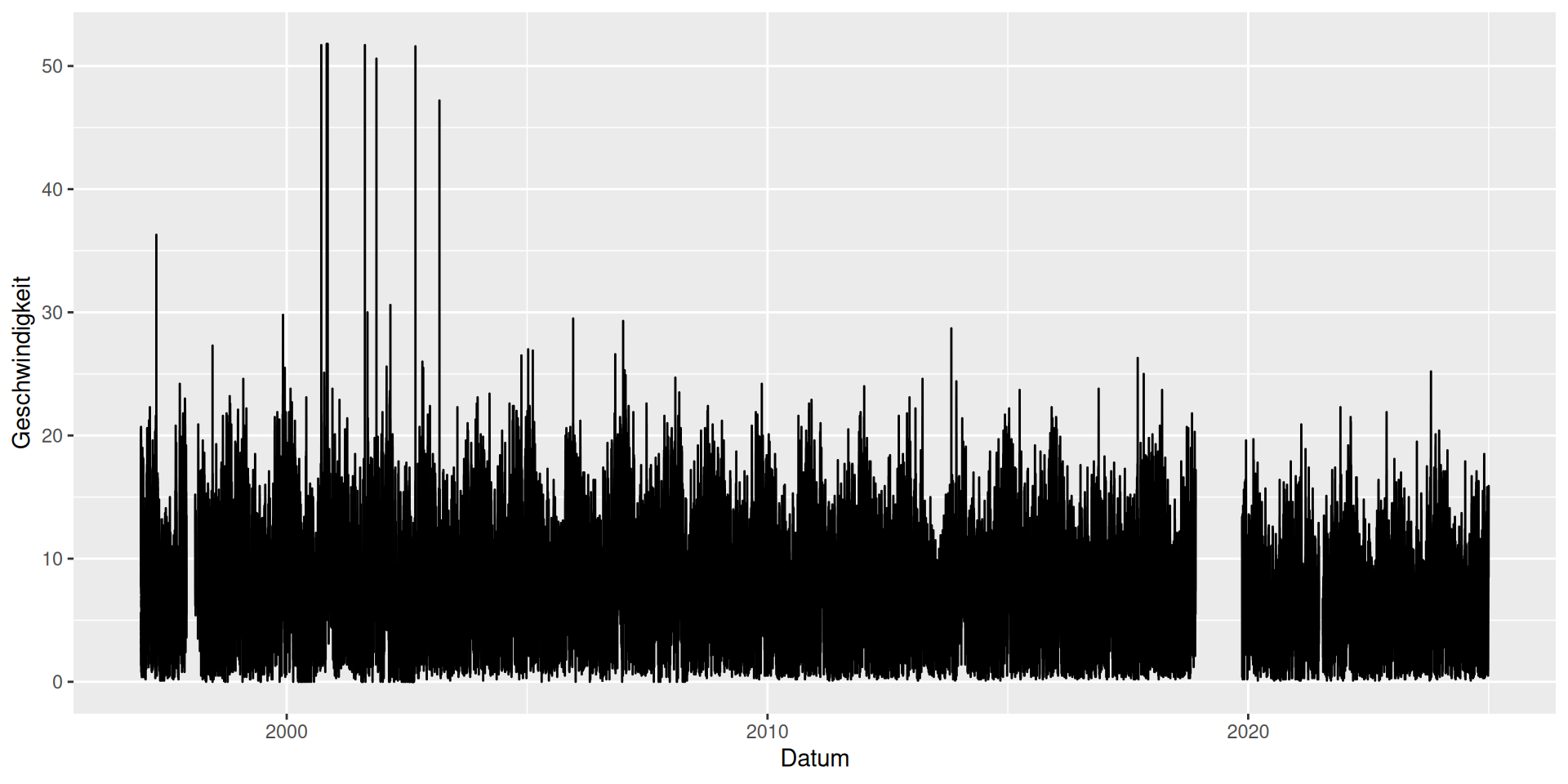
\(\rightarrow\) Lücken werden als Lücken dargestellt
Plot
ggplot(data = d_wind_stark) +
geom_line(mapping = aes(x = Datum, y = v_min_120))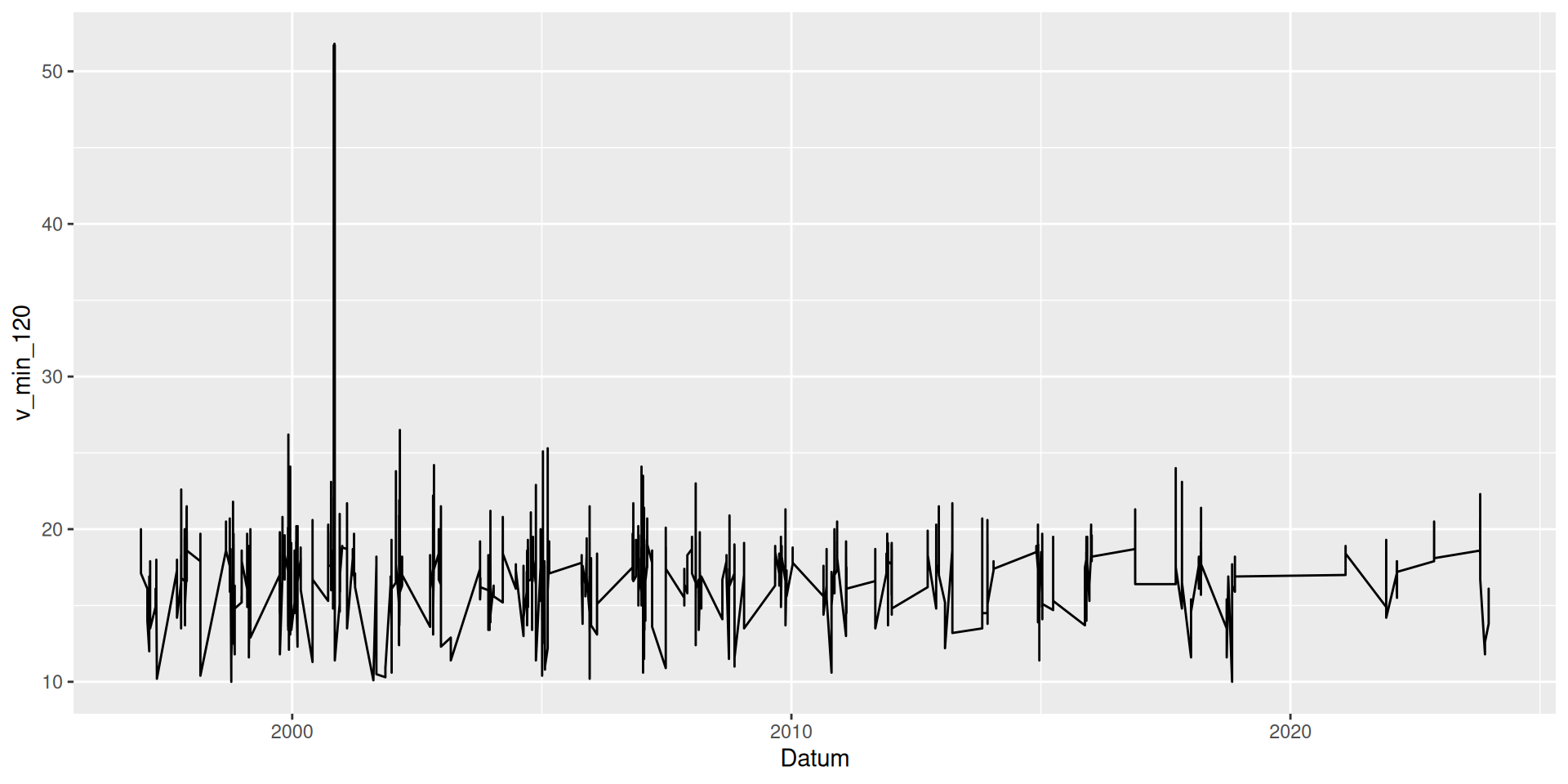
\(\rightarrow\) Einzelne Ereignisse sind nicht zu unterscheiden!
Plotten mit Gruppe
ggplot(data = d_wind_stark_g) +
geom_line(mapping = aes(x = Datum, y = Geschwindigkeit, group = gruppe, color = factor(gruppe)), show.legend = FALSE)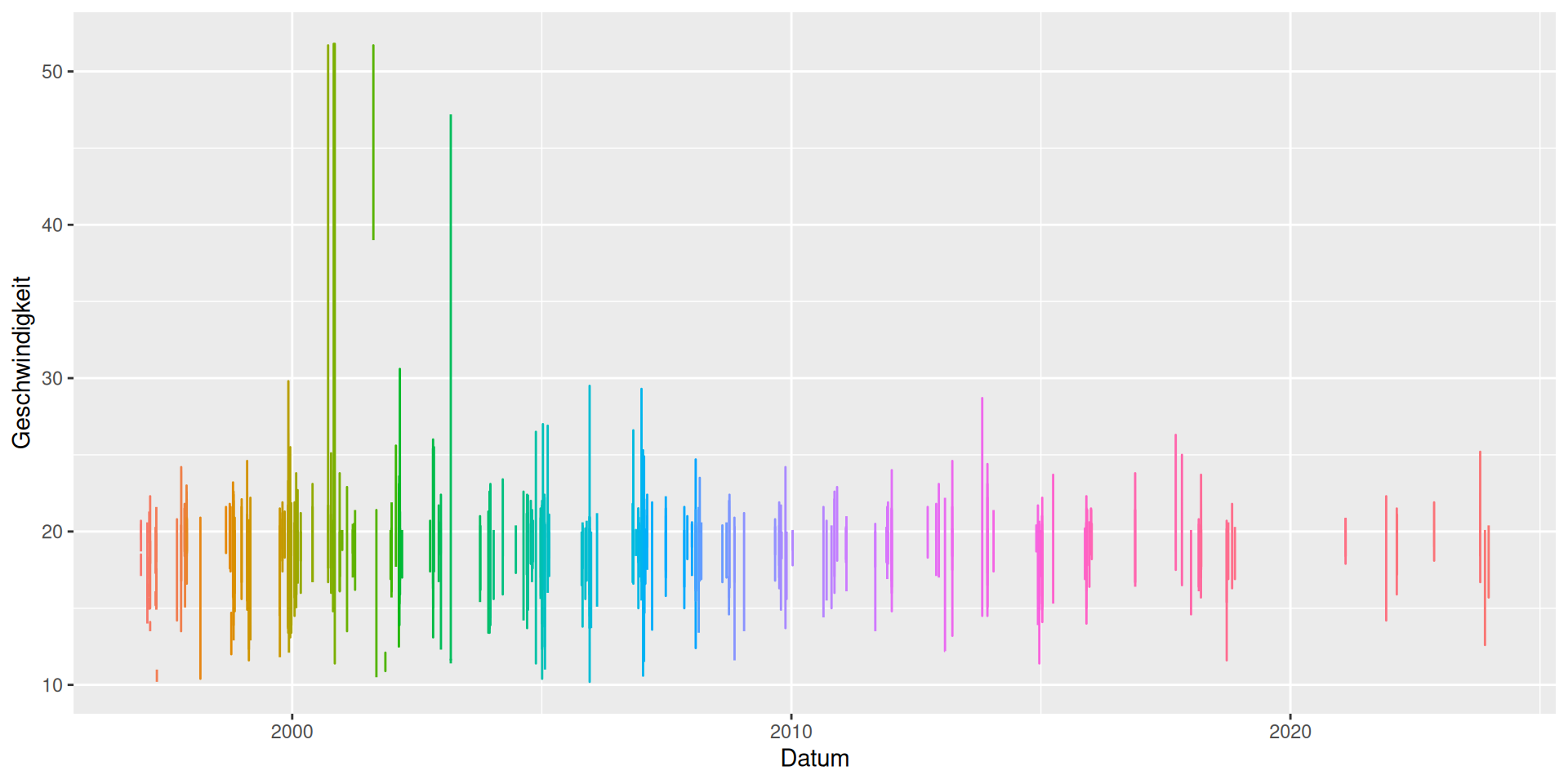
Gruppe 82
ggplot(data = d_wind_stark_g |> filter(gruppe == 82)) +
geom_line(mapping = aes(x = Datum, y = Geschwindigkeit))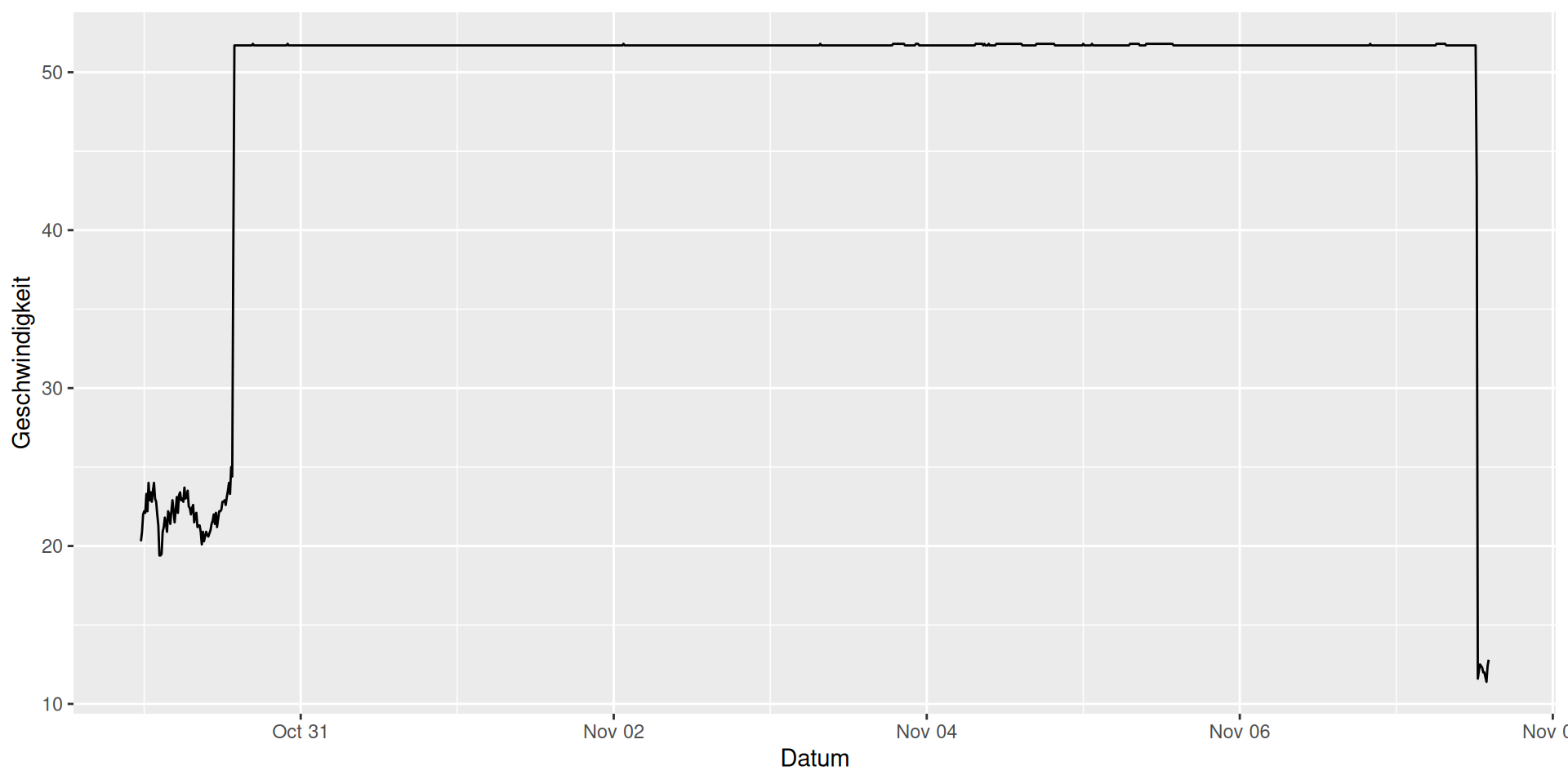
Sieht komisch aus, Rohdaten plotten
Wind im Oktober/November 2000
ggplot(mapping = aes(x = Datum, y = Geschwindigkeit)) +
geom_line(data = d_wind) +
geom_line(data = d_wind_stark_g |> filter(gruppe == 82), color = "hotpink") +
coord_cartesian(xlim = c(dmy_h("29/10/2000:12"), dmy_h("8/11/2000:0")))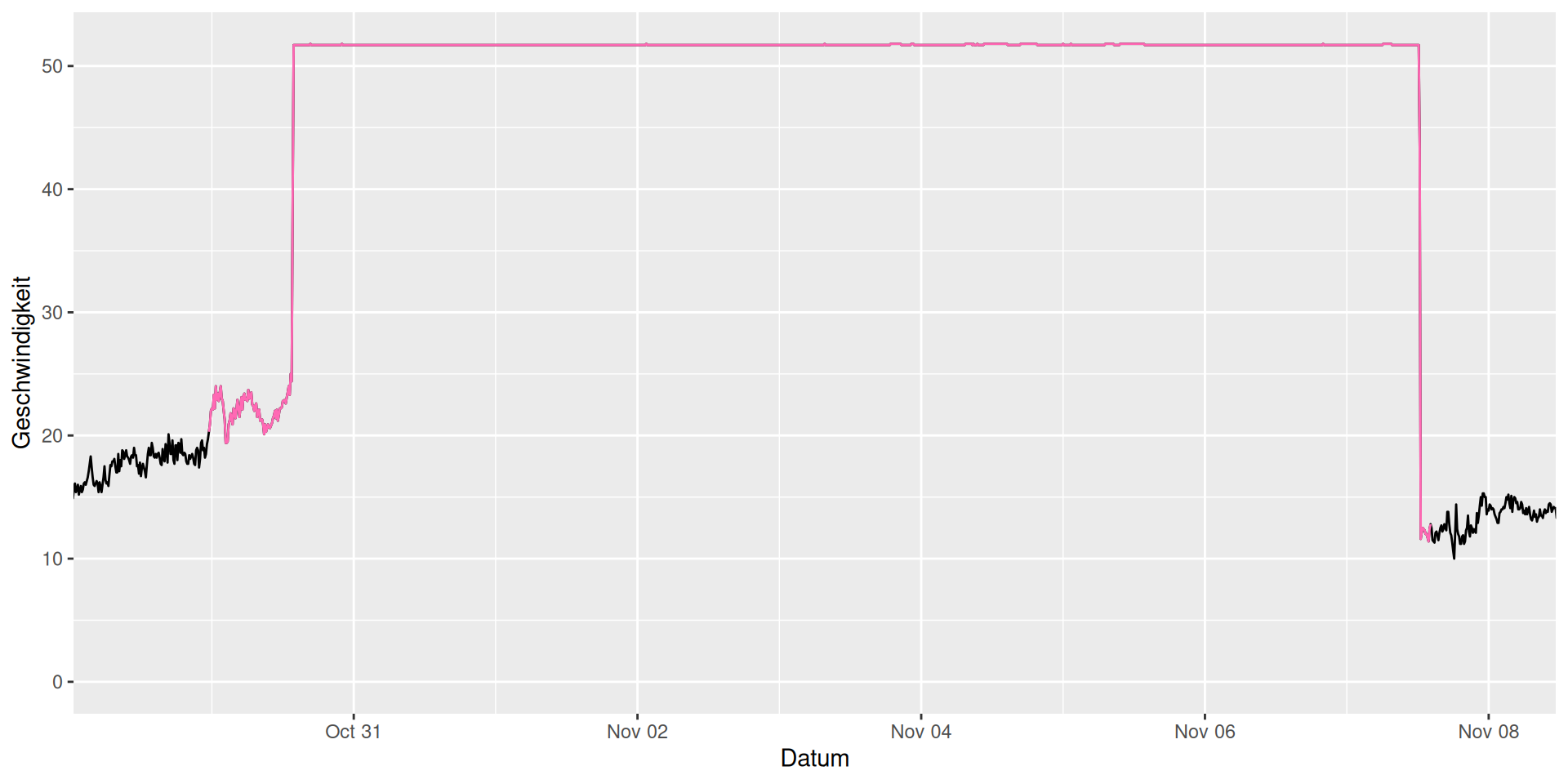
Plateau nicht realistisch, Vermutung: Messgerät im Orkan Oratia kaputt gegangen. Müsste man bei der Auswertung berücksichtigen.
Histogramm Windgeschwindigkeiten
ggplot(data = d_starkwindereignisse) +
geom_histogram(mapping = aes(x = v_max), binwidth = 0.5)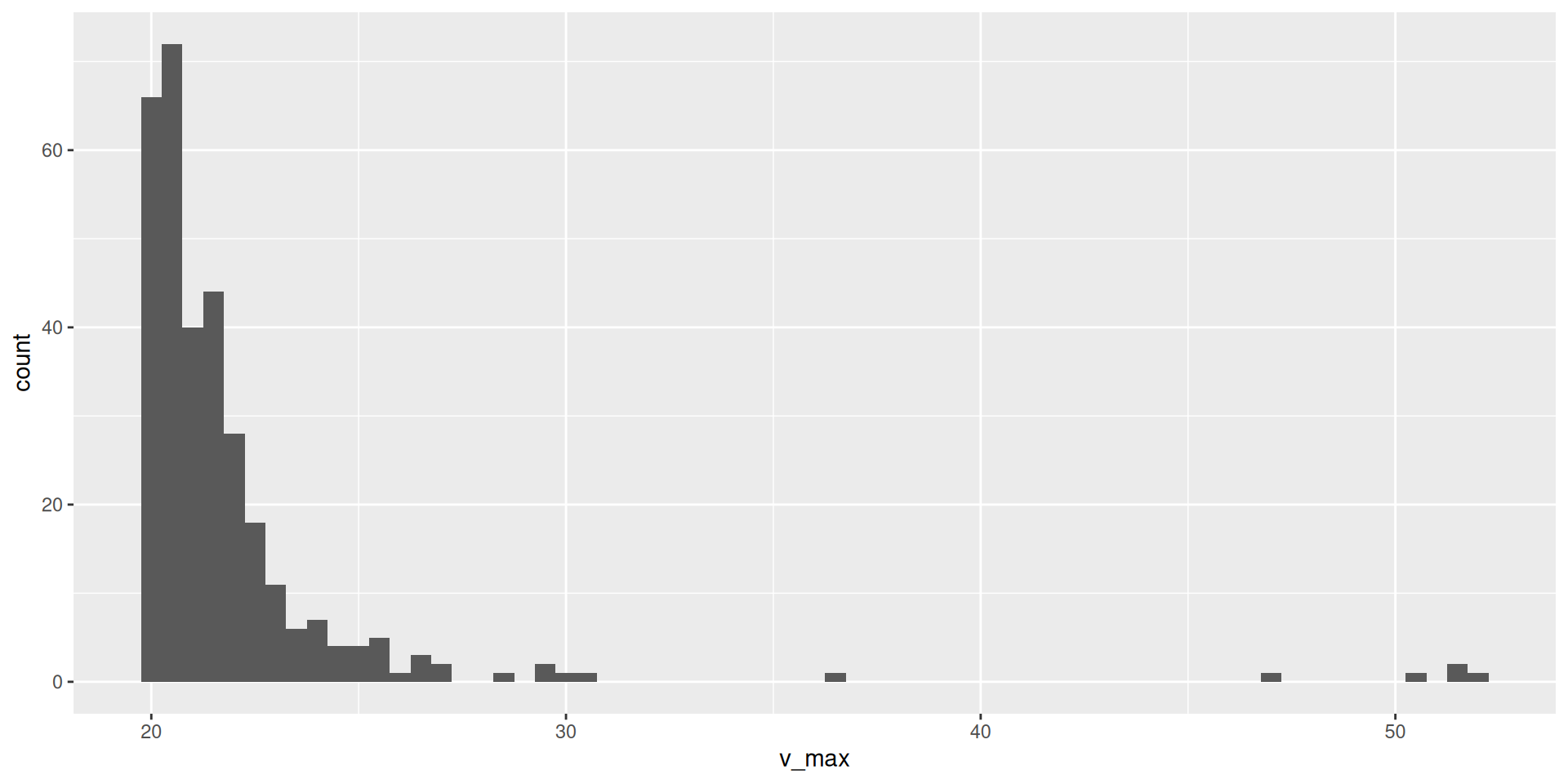
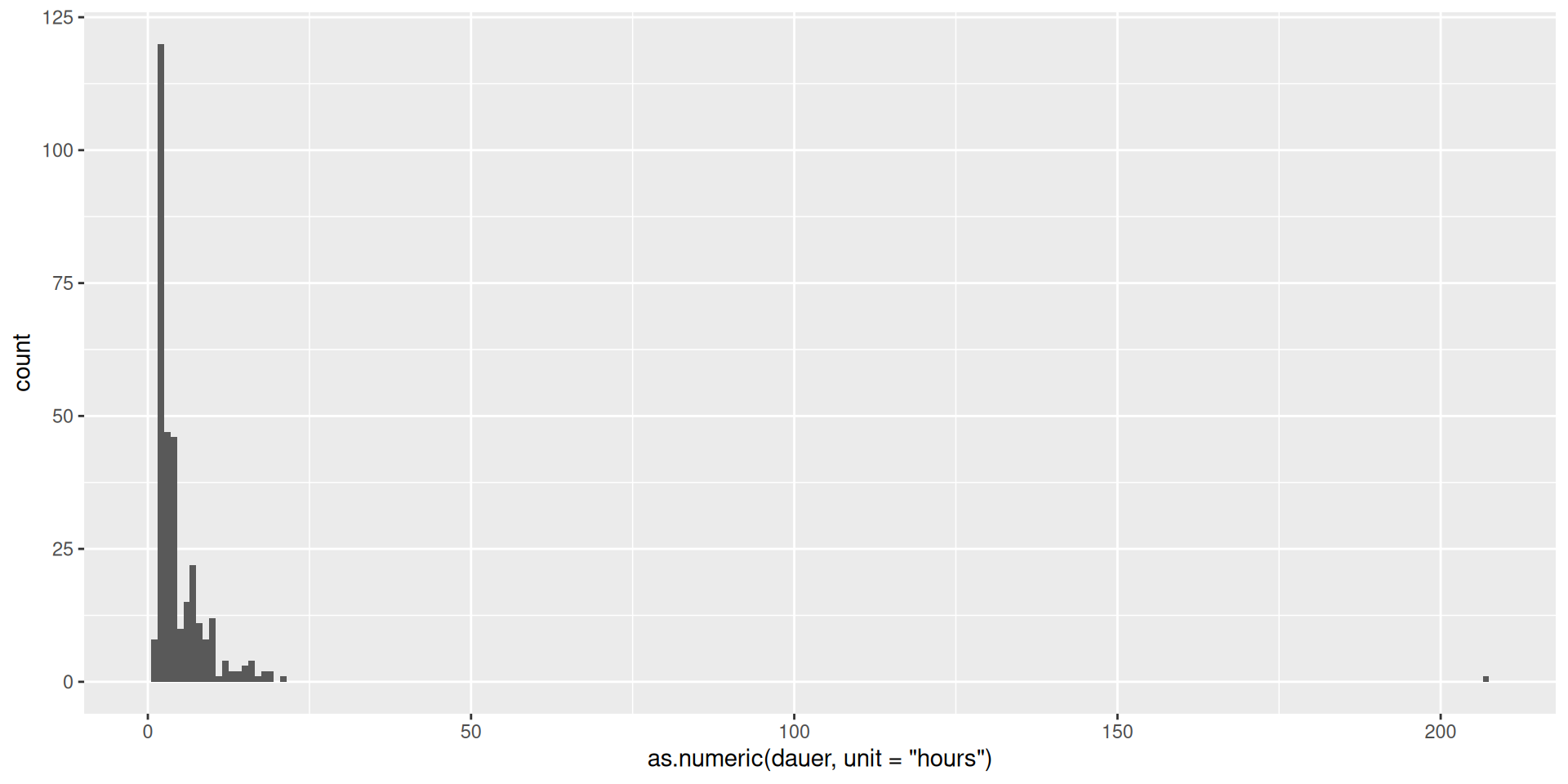
Histogramm Dauer
ggplot(data = d_starkwindereignisse) +
geom_histogram(mapping = aes(x = as.numeric(dauer, unit = "hours")), binwidth = 1)